




[App 개발] SSE 최적화 (0) 서
hongjuny
71.♡.50.179
2009.02.16 12:05
1,366
1
0
0
본문
맥이 인텔 프로세서를 사용한 지 어언 수 년이 흐르고, 이제 자연스럽게 인텔 프로세서의 장점을 십분 활용하는 방법을 강구하여야 하겠습니다.
예전에 제가 본 게시판에 게재했던 '코드 최적화' 글들을 같이 참조하시면 도움이 되실 것입니다.
대장정의 길을 접어들기 전, 먼저 제가 보유한 아이맥 2.4 GHz 에서 배밀도 부동소숫점 매트릭스 연산의 성능이 어느 정도나 나오는지를 확인하는 것이 필요할 것 같습니다.
지난 번에도 그런 것처럼, 캐시 메모리의 유용성을 다시 한 번 확인해 보겠습니다.
제 아이맥은 펜린 프로세서 제품이 아닙니다. 따라서 L1 캐시는 코드와 데이터 따로 해서 각각 32KB 씩 구비하고 있고, L2 캐시는 총 4MB 를 보유하고 있습니다. 따라서 매트릭스 a 와 b 를 곱해서 c 에 넣는 연산을 가정했을 때, L1 데이터 캐시 내에서 세 개의 매트릭스가 모두 들어있을 때의 연산이 가장 확실한 성능을 보장하겠지요. 아니면 적어도 L2 캐시까지는 맞게끔 데이터 버퍼를 나누어 놓는 것이 최적화의 첫 걸음이 되겠습니다.
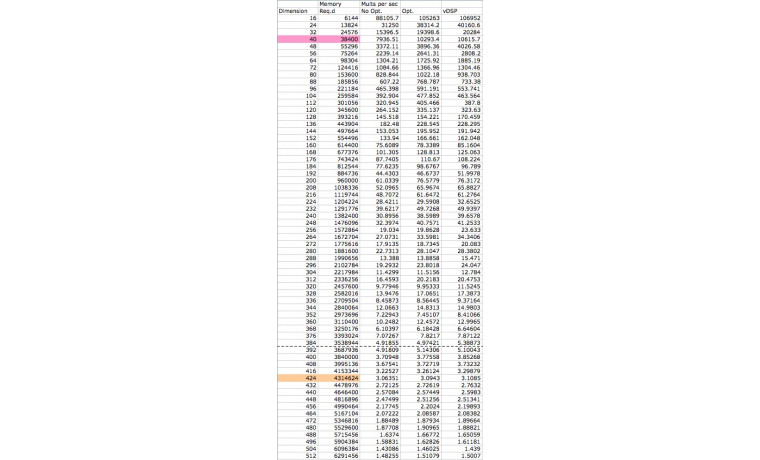
실험 결과를 테이블로 만들어 보았습니다. 매트릭스 크기를 늘여 가면서 측정한 속도에서는 확실히 캐시 메모리의 효과를 살펴볼 수 있습니다. L1 데이터 캐시의 크기인 32768 바이트를 넘어선 40x40 매트릭스 연산 전후 부분에서 더 깊은 속도 저하를 관찰할 수 있습니다. 그 이후로부터는 매트릭스 크기에 따라서 캐시가 깨어지고 데이터를 패치하는 확률에 따라서 속도가 들쭉날쭉 변하는 재미있는 모습을 볼 수 있습니다. 그리고, L2 캐시의 크기인 4,194,304 바이트 지점에 약간 못 미치는 400x400 매트릭스 연산 부분에서 또 다시 급격한 속도 저하를 볼 수 있습니다. 그 이후부터는 메인 메모리와의 데이터 패치가 계속 속도를 떨어뜨리고 있지요.
본 실험은 배밀도 부동소숫점 연산이기 때문에, SSE 연산 플래그를 세팅한 두 번째 열, 그리고 vDSP 를 이용한 세 번째 열의 속도 이득이 그리 크지 않다는 것이 흥미로웠습니다. 향후 프로젝트는 수작업으로 이 차이를 얼마나 더 벌일 수 있을까 하는 것이 도전 과제가 되겠습니다.
예전에 제가 본 게시판에 게재했던 '코드 최적화' 글들을 같이 참조하시면 도움이 되실 것입니다.
대장정의 길을 접어들기 전, 먼저 제가 보유한 아이맥 2.4 GHz 에서 배밀도 부동소숫점 매트릭스 연산의 성능이 어느 정도나 나오는지를 확인하는 것이 필요할 것 같습니다.
지난 번에도 그런 것처럼, 캐시 메모리의 유용성을 다시 한 번 확인해 보겠습니다.
제 아이맥은 펜린 프로세서 제품이 아닙니다. 따라서 L1 캐시는 코드와 데이터 따로 해서 각각 32KB 씩 구비하고 있고, L2 캐시는 총 4MB 를 보유하고 있습니다. 따라서 매트릭스 a 와 b 를 곱해서 c 에 넣는 연산을 가정했을 때, L1 데이터 캐시 내에서 세 개의 매트릭스가 모두 들어있을 때의 연산이 가장 확실한 성능을 보장하겠지요. 아니면 적어도 L2 캐시까지는 맞게끔 데이터 버퍼를 나누어 놓는 것이 최적화의 첫 걸음이 되겠습니다.
실험 결과를 테이블로 만들어 보았습니다. 매트릭스 크기를 늘여 가면서 측정한 속도에서는 확실히 캐시 메모리의 효과를 살펴볼 수 있습니다. L1 데이터 캐시의 크기인 32768 바이트를 넘어선 40x40 매트릭스 연산 전후 부분에서 더 깊은 속도 저하를 관찰할 수 있습니다. 그 이후로부터는 매트릭스 크기에 따라서 캐시가 깨어지고 데이터를 패치하는 확률에 따라서 속도가 들쭉날쭉 변하는 재미있는 모습을 볼 수 있습니다. 그리고, L2 캐시의 크기인 4,194,304 바이트 지점에 약간 못 미치는 400x400 매트릭스 연산 부분에서 또 다시 급격한 속도 저하를 볼 수 있습니다. 그 이후부터는 메인 메모리와의 데이터 패치가 계속 속도를 떨어뜨리고 있지요.
본 실험은 배밀도 부동소숫점 연산이기 때문에, SSE 연산 플래그를 세팅한 두 번째 열, 그리고 vDSP 를 이용한 세 번째 열의 속도 이득이 그리 크지 않다는 것이 흥미로웠습니다. 향후 프로젝트는 수작업으로 이 차이를 얼마나 더 벌일 수 있을까 하는 것이 도전 과제가 되겠습니다.
0
0
로그인 후 추천 또는 비추천하실 수 있습니다.
최신글이 없습니다.
최신글이 없습니다.



댓글목록 1
진희성님의 댓글
- 진희성님의 홈
- 전체게시물
- 아이디로 검색
210.♡.0.253 2009.03.06 17:57알아 들을듯하면서도 어렵네요.. 고생고생...