




[App 개발] CUDA, Supercomputing for the Masses (1)
hongjuny
130.♡.132.177
2009.08.16 03:39
2,146
1
0
0
-
- 관련링크 : http://www.ddj.com/cpp/2072006591회 연결
-
- 관련링크 : http://www.ddj.com/cpp/2072006592회 연결
본문
CUDA, Supercomputing for the Masses
Rob Farber
April 15, 2008
CUDA 는 GPU 상에서 동작하는 소프트웨어를 쉽게 개발하는 기법을 제공합니다.
C 와 같은 고급언어를 사용하면서도 멀티코어보다 수 배 이상 빠른 속도를 얻고 싶으신가요? 그리고 디바이스의 갯수를 늘리면 그만큼 속도를 얻을 수 있는 방법을 원하시나요?
저를 포함한 많은 사람들이 이러한 성능과 확장성을 NVIDIA 에서 GPU 의 멀티 쓰레드 프로그래밍을 지원하도록 설계된 CUDA (Compute Unified Device Architecture) 로부터 획득하였습니다. 저는 "프로그래밍" 이라는 말을 강조하고 싶습니다. 왜냐하면 CUDA 는 여러분의 프로그램을 라이브러리에 맞도록 구겨넣지 않고, 여러분의 작업에 전념할 수 있도록 만들어진 구조이기 때문입니다. CUDA 는 여러분이 작성한 소프트웨어를 멀티 쓰레드 하드웨어를 이용해서 최고의 성능을 갖추도록 도와줄 것입니다. 그리고 합리적이면서 쉬운 소프트웨어 개발 환경 하에서 적합한 매핑을 찾는 작업을 즐기실 수 있을 것입니다.
이번 첫 번째 연재 글에서는 예제를 통해 CUDA 의 성능을 소개하면서, 프로그램을 고성능화할 수 있도록 멀티 쓰레드 환경에 적용하는 방법을 소개하겠습니다. 물론, 모든 문제를 다 멀티 쓰레드 하드웨어에 효과적으로 적용할 수는 없습니다, 따라서 제 글에서는 가능한 경우와 불가능한 경우를 소개하면서, 최대 가능한 작업이 어떤 것인지에 대한 기본 개념을 제공하도록 하겠습니다.
CUDA 는 GPU 에서 동작하기는 하지만, "CUDA 프로그래밍" 과 "GPGPU 프로그래밍" 은 다른 말입니다. 그전까지는 GUP 용 소프트웨어를 만든다는 것은 GPU 언어로 프로그래밍한다는 뜻이었습니다. 어느 지인은 이 작업을, 눈이 어디를 보고 있는지를 팔꿈치를 보고 알아내는 작업이라고 비유하였습니다. CUDA 는 GPU 에서 동작하는 소프트웨어를 익숙한 프로그래밍 언어로 작성하게끔 해 줍니다. 또한 고성능을 위하여 소프트웨어를 하드웨어 맞게끔 직접 컴파일(예를들어 GPU 어셈블리 언어) 을 함으로써 그래픽 레이어 API 의 부하를 방지하기도 합니다.
CUDA 장치는 여러분이 선택하십시오. 그림 1 과 2 는 CUDA N-body 시뮬레이터 프로그램을 랩탑과 GPU 가 탑재된 데스크탑 피씨에서 동작하는 모습입니다.
<그림>
CUDA 가 실제로 소프트웨어의 성능을 수십, 수백 배 빠르게 할 수 있을까요? 아니면 그저 과대 선전일까요?
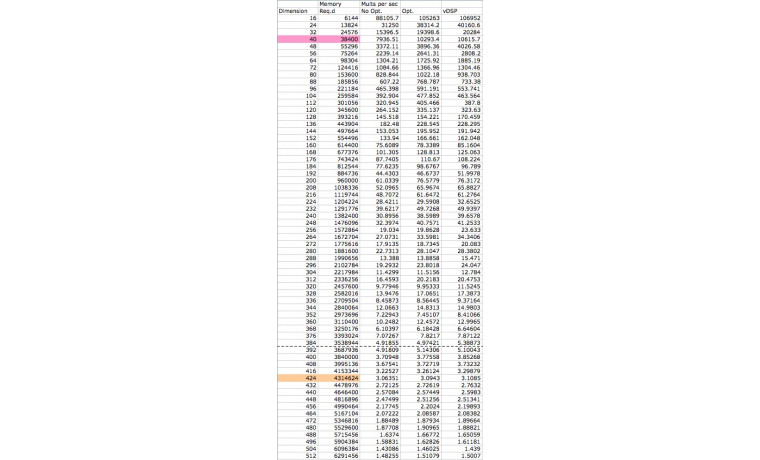
CUDA 는 신기술이긴 하지만 서적이나 인터넷 등에 소개된 예제들을 통하여 현용 GPU 를 이용한 현저한 성능 향상을 찾아볼 수 있습니다. 표 1과 2에서는 NVIDIA 와 Beckman Institute 웹사이트에 소개된 내용을 정리한 것입니다. CUDA 의 핵심은 수천 개의 쓰레드를 손쉽게 운용하는 프로그래밍 기술입니다. 현 세대 NVIDIA GPU 들은 상당히 많은 수의 쓰레드를 사용할 수 있으며, 따라서 응용프로그램 성능을 수십에서 수백 배 증가시킬 수 있습니다. 이러한 그래픽 프로세서들을 적절한 가격에 누구나 쉽게 구입할 수 있습니다. 신형 그래픽 카드들은 더 넓은 메모리 밴드폭과 비대칭형 데이터 교환, atomic operation, 그리고 배밀도 부동소숫점 계산 성능 등을 제공하여 CUDA 의 성능을 더욱 향상시켜줄 것입니다. 기술 진화에 따른 CUDA 소프트웨어 환경의 확장성을 볼 때, 결국 GPU 와 멀티 코어 프로세서의 성능 차이를 거의 구별하기 어렵게 될 것입니다. 개발자로서 수천 개의 쓰레드를 활용한 응용프로그램 환경이 보편화되고 CUDA 가 범용 프로세서와 함께 많은 플랫폼에서 활용되기를 기대합니다.
1980년도 로스 알라모스 국립 연구소 연구원으로 있을 당시 65,536 개의 병렬 프로세서를 탑재한 Thinking Machines 슈퍼컴퓨터를 이용하곤 하였습니다. CUDA 는 현대적인 대량 쓰레드 환경 하에서 다시 작업할 수 있게끔 간편하면서 고성능의 프레임웍을 제공하였습니다. 제 코드 중 하나는 이제 CUDA 로 작성되어 NVIDIA GPU 에서 동작되며, 2.6GHz 쿼드 코어 옵테른 프로세서 시스템과 비교했을 때 거의 백 배의 성능 향상을 나타내었습니다.
CUDA 지원 그래픽 프로세서는 호스트 컴퓨터 내에서 코프로세서 역할을 수행합니다. 다시 말해 GPU 는 호스트 컴퓨터와 분리되어 독립된 메모리와 프로세싱 엘리먼트를 갖고 있는 것으로 간주됩니다. 어떤 작업을 수행하게 하려면 데이터가 호스트 컴퓨터와 CUDA 장비의 메모리 공간 사이에서 교환되어야 합니다. 따라서 성능 측정시 유효한 IO 타임을 포함해야 합니다. 제 친구는 이 점을 "정직한 플롭스" 라고 표현했는데, 왜냐하면 이것이 응용프로그램의 실제 성능을 더 정확히 반영하기 때문입니다.
저는 현용 기술에 비하여 수십에서 수백 배의 성능 향상을 컴퓨팅의 한 측면을 심대하게 변형시키는 파괴적인 변화라고 주장합니다. 예를 들어, 예전에 1년 걸리던 작업이 이제 며칠, 혹은 몇 시간 내에 완수되며, 긴 시간이 걸리던 작업이 새로운 기술로 인하여 수 초 내에 종결되는 즉응적인 작업이 되며, 예전에는 실시간 처리가 어려웠던 작업들이 가능해집니다. 결국 쓰레드화된 병렬 소프트웨어 작성 기술을 습득한 컨설턴트와 엔지니어에게 큰 이득을 가져다줄 수 있습니다. 여러분은 어떠신지요? 이러한 컴퓨팅 기능이 여러분의 직책이나 응용프로램, 혹은 실시간 프로세싱 작업에 도움이 될 수 있을까요?
만약 새 그래픽 프로세서 카드를 장만하신다면, 먼저 제 글들을 읽어보시기를 권합니다. 계속해서 다양한 하드웨어의 특성들 (메모리 밴드폭, 레지스터의 갯수, 아토믹 오퍼레이션 등) 이 프로그램 성능에 어떤 영향을 미치는지 소개할 것이며, 여러분의 응용프로그램에 맞는 하드웨어 선택에 도움이 될 것입니다. 그리고 어떤 하드웨어를 구입할 것인지 등을 포함한 CUDA 에 관련된 다양한 정보들을 CUDA Zone 포럼에서 보실 수 있습니다.
CUDA Toolkit 을 설치하시면 C 언어 소프트웨어 개발에 필요한 다양한 툴이 제공됩니다.
* nvcc C 컴파일러
* GPU 를 이용한 CUDA FFT 와 BLAS 라이브러리
* 프로파일러
* GPU 용 gdb 디버거
* CUDA 런타임 드라이버
* CUDA 프로그래밍 매뉴얼
nvcc C 컴파일러는 C 코드를 GPU 나 에뮬레이터에서 동작할 실행파일로 변경하는 대부분의 작업을 수행합니다. 다행히도 고성능을 발휘하기 위해 어셈블리 언어를 필요로 하지는 않습니다. 향후 C++, FORTRAN, Python 등의 고급 언어에서 CUDA 를 사용하는 방법을 소개할 것입니다. C/C++ 에는 익숙한 것으로 간주하겠습니다. 병렬 프로그래밍이나 CUDA 에 대한 경험은 필요 없습니다. 이 글은 기존 CUDA 문서와 일관된 내용을 담고 있습니다.
CUDA C 언어 프로그램을 작성하고 실행하는 것은 기존 C 프로그래밍 환경의 작업과 동일합니다. 윈도우와 리눅스 환경 하에서 특별한 컴파일 및 실행 방법이 CUDA 문서에 나와 있습니다만, 그 내용은
1. 문서편집기로 CUDA 프로그램을 만들고 수정한다. CUDA C 언어 프로그램은 ".cu" 확장자를 사용한다.
2. nvcc 를 이용하여 프로그램을 컴파일하여 실행모듈을 만든다. (NVIDIA 에서는 예제와 함께 적당한 makefile 을 제공한다. 일반적으로 "make" 명령을 이용해서 CUDA 장비용 모듈을 만들거나, "make emu=1" 명령으로 에뮬레이터용 모듈을 만든다.)
3. 실행모듈을 실행한다.
다음 리스트는 간단한 CUDA 프로그램입니다. 이 프로그램은 CUDA 장비로 데이터를 교환하는 CUDA API 를 호출하는 내용입니다. 개발툴을 사용해서 컴파일하고 CUDA 프로그램을 실행하는 데 있어서 까다롭거나 한 내용은 들어있지 않습니다. 다음 글에서는 CUDA 장비를 이용해서 작업 수행을 시작하는 내용을 다루도록 하겠습니다.
// moveArrays.cu
//
// demonstrates CUDA interface to data allocation on device (GPU)
// and data movement between host (CPU) and device.
#include
#include
#include
int main(void)
{
float *a_h, *b_h; // pointers to host memory
float *a_d, *b_d; // pointers to device memory
int N = 14;
int i;
// allocate arrays on host
a_h = (float *)malloc(sizeof(float)*N);
b_h = (float *)malloc(sizeof(float)*N);
// allocate arrays on device
cudaMalloc((void **) &a_d, sizeof(float)*N);
cudaMalloc((void **) &b_d, sizeof(float)*N);
// initialize host data
for (i=0; i a_h[i] = 10.f+i;
b_h[i] = 0.f;
}
// send data from host to device: a_h to a_d
cudaMemcpy(a_d, a_h, sizeof(float)*N, cudaMemcpyHostToDevice);
// copy data within device: a_d to b_d
cudaMemcpy(b_d, a_d, sizeof(float)*N, cudaMemcpyDeviceToDevice);
// retrieve data from device: b_d to b_h
cudaMemcpy(b_h, b_d, sizeof(float)*N, cudaMemcpyDeviceToHost);
// check result
for (i=0; i assert(a_h[i] == b_h[i]);
// cleanup
free(a_h); free(b_h);
cudaFree(a_d); cudaFree(b_d);
Listing One
한 번 개발장비를 이용해서 작업을 해 보세요. 초심자 분들에게: 에뮬레이터에서 (make emu=1 명령으로 빌드) 동작시키면서 GPU 내에서 어떤 일이 일어나고 있는지를 printf 구문을 이용해서 살펴볼 수 있습니다. 그리고 디버거도 한 번 이용해 보세요.
Rob Farber
April 15, 2008
CUDA 는 GPU 상에서 동작하는 소프트웨어를 쉽게 개발하는 기법을 제공합니다.
C 와 같은 고급언어를 사용하면서도 멀티코어보다 수 배 이상 빠른 속도를 얻고 싶으신가요? 그리고 디바이스의 갯수를 늘리면 그만큼 속도를 얻을 수 있는 방법을 원하시나요?
저를 포함한 많은 사람들이 이러한 성능과 확장성을 NVIDIA 에서 GPU 의 멀티 쓰레드 프로그래밍을 지원하도록 설계된 CUDA (Compute Unified Device Architecture) 로부터 획득하였습니다. 저는 "프로그래밍" 이라는 말을 강조하고 싶습니다. 왜냐하면 CUDA 는 여러분의 프로그램을 라이브러리에 맞도록 구겨넣지 않고, 여러분의 작업에 전념할 수 있도록 만들어진 구조이기 때문입니다. CUDA 는 여러분이 작성한 소프트웨어를 멀티 쓰레드 하드웨어를 이용해서 최고의 성능을 갖추도록 도와줄 것입니다. 그리고 합리적이면서 쉬운 소프트웨어 개발 환경 하에서 적합한 매핑을 찾는 작업을 즐기실 수 있을 것입니다.
이번 첫 번째 연재 글에서는 예제를 통해 CUDA 의 성능을 소개하면서, 프로그램을 고성능화할 수 있도록 멀티 쓰레드 환경에 적용하는 방법을 소개하겠습니다. 물론, 모든 문제를 다 멀티 쓰레드 하드웨어에 효과적으로 적용할 수는 없습니다, 따라서 제 글에서는 가능한 경우와 불가능한 경우를 소개하면서, 최대 가능한 작업이 어떤 것인지에 대한 기본 개념을 제공하도록 하겠습니다.
CUDA 는 GPU 에서 동작하기는 하지만, "CUDA 프로그래밍" 과 "GPGPU 프로그래밍" 은 다른 말입니다. 그전까지는 GUP 용 소프트웨어를 만든다는 것은 GPU 언어로 프로그래밍한다는 뜻이었습니다. 어느 지인은 이 작업을, 눈이 어디를 보고 있는지를 팔꿈치를 보고 알아내는 작업이라고 비유하였습니다. CUDA 는 GPU 에서 동작하는 소프트웨어를 익숙한 프로그래밍 언어로 작성하게끔 해 줍니다. 또한 고성능을 위하여 소프트웨어를 하드웨어 맞게끔 직접 컴파일(예를들어 GPU 어셈블리 언어) 을 함으로써 그래픽 레이어 API 의 부하를 방지하기도 합니다.
CUDA 장치는 여러분이 선택하십시오. 그림 1 과 2 는 CUDA N-body 시뮬레이터 프로그램을 랩탑과 GPU 가 탑재된 데스크탑 피씨에서 동작하는 모습입니다.
<그림>
CUDA 가 실제로 소프트웨어의 성능을 수십, 수백 배 빠르게 할 수 있을까요? 아니면 그저 과대 선전일까요?
CUDA 는 신기술이긴 하지만 서적이나 인터넷 등에 소개된 예제들을 통하여 현용 GPU 를 이용한 현저한 성능 향상을 찾아볼 수 있습니다. 표 1과 2에서는 NVIDIA 와 Beckman Institute 웹사이트에 소개된 내용을 정리한 것입니다. CUDA 의 핵심은 수천 개의 쓰레드를 손쉽게 운용하는 프로그래밍 기술입니다. 현 세대 NVIDIA GPU 들은 상당히 많은 수의 쓰레드를 사용할 수 있으며, 따라서 응용프로그램 성능을 수십에서 수백 배 증가시킬 수 있습니다. 이러한 그래픽 프로세서들을 적절한 가격에 누구나 쉽게 구입할 수 있습니다. 신형 그래픽 카드들은 더 넓은 메모리 밴드폭과 비대칭형 데이터 교환, atomic operation, 그리고 배밀도 부동소숫점 계산 성능 등을 제공하여 CUDA 의 성능을 더욱 향상시켜줄 것입니다. 기술 진화에 따른 CUDA 소프트웨어 환경의 확장성을 볼 때, 결국 GPU 와 멀티 코어 프로세서의 성능 차이를 거의 구별하기 어렵게 될 것입니다. 개발자로서 수천 개의 쓰레드를 활용한 응용프로그램 환경이 보편화되고 CUDA 가 범용 프로세서와 함께 많은 플랫폼에서 활용되기를 기대합니다.
1980년도 로스 알라모스 국립 연구소 연구원으로 있을 당시 65,536 개의 병렬 프로세서를 탑재한 Thinking Machines 슈퍼컴퓨터를 이용하곤 하였습니다. CUDA 는 현대적인 대량 쓰레드 환경 하에서 다시 작업할 수 있게끔 간편하면서 고성능의 프레임웍을 제공하였습니다. 제 코드 중 하나는 이제 CUDA 로 작성되어 NVIDIA GPU 에서 동작되며, 2.6GHz 쿼드 코어 옵테른 프로세서 시스템과 비교했을 때 거의 백 배의 성능 향상을 나타내었습니다.
CUDA 지원 그래픽 프로세서는 호스트 컴퓨터 내에서 코프로세서 역할을 수행합니다. 다시 말해 GPU 는 호스트 컴퓨터와 분리되어 독립된 메모리와 프로세싱 엘리먼트를 갖고 있는 것으로 간주됩니다. 어떤 작업을 수행하게 하려면 데이터가 호스트 컴퓨터와 CUDA 장비의 메모리 공간 사이에서 교환되어야 합니다. 따라서 성능 측정시 유효한 IO 타임을 포함해야 합니다. 제 친구는 이 점을 "정직한 플롭스" 라고 표현했는데, 왜냐하면 이것이 응용프로그램의 실제 성능을 더 정확히 반영하기 때문입니다.
저는 현용 기술에 비하여 수십에서 수백 배의 성능 향상을 컴퓨팅의 한 측면을 심대하게 변형시키는 파괴적인 변화라고 주장합니다. 예를 들어, 예전에 1년 걸리던 작업이 이제 며칠, 혹은 몇 시간 내에 완수되며, 긴 시간이 걸리던 작업이 새로운 기술로 인하여 수 초 내에 종결되는 즉응적인 작업이 되며, 예전에는 실시간 처리가 어려웠던 작업들이 가능해집니다. 결국 쓰레드화된 병렬 소프트웨어 작성 기술을 습득한 컨설턴트와 엔지니어에게 큰 이득을 가져다줄 수 있습니다. 여러분은 어떠신지요? 이러한 컴퓨팅 기능이 여러분의 직책이나 응용프로램, 혹은 실시간 프로세싱 작업에 도움이 될 수 있을까요?
만약 새 그래픽 프로세서 카드를 장만하신다면, 먼저 제 글들을 읽어보시기를 권합니다. 계속해서 다양한 하드웨어의 특성들 (메모리 밴드폭, 레지스터의 갯수, 아토믹 오퍼레이션 등) 이 프로그램 성능에 어떤 영향을 미치는지 소개할 것이며, 여러분의 응용프로그램에 맞는 하드웨어 선택에 도움이 될 것입니다. 그리고 어떤 하드웨어를 구입할 것인지 등을 포함한 CUDA 에 관련된 다양한 정보들을 CUDA Zone 포럼에서 보실 수 있습니다.
CUDA Toolkit 을 설치하시면 C 언어 소프트웨어 개발에 필요한 다양한 툴이 제공됩니다.
* nvcc C 컴파일러
* GPU 를 이용한 CUDA FFT 와 BLAS 라이브러리
* 프로파일러
* GPU 용 gdb 디버거
* CUDA 런타임 드라이버
* CUDA 프로그래밍 매뉴얼
nvcc C 컴파일러는 C 코드를 GPU 나 에뮬레이터에서 동작할 실행파일로 변경하는 대부분의 작업을 수행합니다. 다행히도 고성능을 발휘하기 위해 어셈블리 언어를 필요로 하지는 않습니다. 향후 C++, FORTRAN, Python 등의 고급 언어에서 CUDA 를 사용하는 방법을 소개할 것입니다. C/C++ 에는 익숙한 것으로 간주하겠습니다. 병렬 프로그래밍이나 CUDA 에 대한 경험은 필요 없습니다. 이 글은 기존 CUDA 문서와 일관된 내용을 담고 있습니다.
CUDA C 언어 프로그램을 작성하고 실행하는 것은 기존 C 프로그래밍 환경의 작업과 동일합니다. 윈도우와 리눅스 환경 하에서 특별한 컴파일 및 실행 방법이 CUDA 문서에 나와 있습니다만, 그 내용은
1. 문서편집기로 CUDA 프로그램을 만들고 수정한다. CUDA C 언어 프로그램은 ".cu" 확장자를 사용한다.
2. nvcc 를 이용하여 프로그램을 컴파일하여 실행모듈을 만든다. (NVIDIA 에서는 예제와 함께 적당한 makefile 을 제공한다. 일반적으로 "make" 명령을 이용해서 CUDA 장비용 모듈을 만들거나, "make emu=1" 명령으로 에뮬레이터용 모듈을 만든다.)
3. 실행모듈을 실행한다.
다음 리스트는 간단한 CUDA 프로그램입니다. 이 프로그램은 CUDA 장비로 데이터를 교환하는 CUDA API 를 호출하는 내용입니다. 개발툴을 사용해서 컴파일하고 CUDA 프로그램을 실행하는 데 있어서 까다롭거나 한 내용은 들어있지 않습니다. 다음 글에서는 CUDA 장비를 이용해서 작업 수행을 시작하는 내용을 다루도록 하겠습니다.
// moveArrays.cu
//
// demonstrates CUDA interface to data allocation on device (GPU)
// and data movement between host (CPU) and device.
#include
#include
#include
int main(void)
{
float *a_h, *b_h; // pointers to host memory
float *a_d, *b_d; // pointers to device memory
int N = 14;
int i;
// allocate arrays on host
a_h = (float *)malloc(sizeof(float)*N);
b_h = (float *)malloc(sizeof(float)*N);
// allocate arrays on device
cudaMalloc((void **) &a_d, sizeof(float)*N);
cudaMalloc((void **) &b_d, sizeof(float)*N);
// initialize host data
for (i=0; i a_h[i] = 10.f+i;
b_h[i] = 0.f;
}
// send data from host to device: a_h to a_d
cudaMemcpy(a_d, a_h, sizeof(float)*N, cudaMemcpyHostToDevice);
// copy data within device: a_d to b_d
cudaMemcpy(b_d, a_d, sizeof(float)*N, cudaMemcpyDeviceToDevice);
// retrieve data from device: b_d to b_h
cudaMemcpy(b_h, b_d, sizeof(float)*N, cudaMemcpyDeviceToHost);
// check result
for (i=0; i assert(a_h[i] == b_h[i]);
// cleanup
free(a_h); free(b_h);
cudaFree(a_d); cudaFree(b_d);
Listing One
한 번 개발장비를 이용해서 작업을 해 보세요. 초심자 분들에게: 에뮬레이터에서 (make emu=1 명령으로 빌드) 동작시키면서 GPU 내에서 어떤 일이 일어나고 있는지를 printf 구문을 이용해서 살펴볼 수 있습니다. 그리고 디버거도 한 번 이용해 보세요.
0
0
로그인 후 추천 또는 비추천하실 수 있습니다.
최신글이 없습니다.
최신글이 없습니다.



댓글목록 1
hongjuny님의 댓글
- hongjuny님의 홈
- 전체게시물
- 아이디로 검색
130.♡.132.177 2009.08.16 03:40이 글은 DDJ 에 게재되었던 CUDA 프로그래밍 글의 번역입니다. 날림 번역이므로 어디 소문내지 마시고 혼자만 보세요... -_-;