




[App 개발] 코드 최적화 (1) 캐시
hongjuny
151.♡.13.192
2005.08.12 07:23
1,378
0
0
0
본문
이름은 거창하게 지어 봤습니다만, 별 것 아니고요... ㅡㅡ;;; 앞으로 몇 회동안 제가 직접 작성한 코드로 어떻게 하면 빠른 프로그램을 작성할 수 있을까를 같이 한 번 연구해 보았으면 합니다.
보유하고 계신 맥의 종류마다 약간씩 다르지만, 제가 가지고 있는 G5 프로세서는 64K/32K L1 캐시와 512K L2 캐시를 보유하고 있습니다. 그런데 실제로 이 캐시라는 놈이 얼마나 큰 역할을 하는지를 잘 경험해 보기는 쉽지 않지요. 그래서 먼저 캐시가 어떻게 작동하고 있는지를 확인해 보고자 짧은 프로그램을 작성해 보았습니다.
과학 계산 프로그램이건 토토샵이건 간에 그 내용은 모두 다 매트릭스 연산이라고 해도 과언이 아닙니다. 간단한 매트릭스 연산 예제를 한 번 작성해 보았습니다.
for( i = 0 ; i < MAT_SIZE ; i++ ) {
a[ i * MAT_SIZE_2 + 0 ] =
1.0 * a[ i * MAT_SIZE_2 + 12 ] + 2.0 * a[ i * MAT_SIZE_2 + 11 ] +
3.0 * a[ i * MAT_SIZE_2 + 10 ] + 4.0 * a[ i * MAT_SIZE_2 + 9 ] +
5.0 * a[ i * MAT_SIZE_2 + 8 ] + 6.0 * a[ i * MAT_SIZE_2 + 7 ] +
7.0 * a[ i * MAT_SIZE_2 + 6 ] + 8.0 * a[ i * MAT_SIZE_2 + 5 ] +
9.0 * ( a[ i * MAT_SIZE_2 + 4 ] + a[ i * MAT_SIZE_2 + 3 ] + a[ i * MAT_SIZE_2 + 2 ] ) ;
}
여기서 a 라는 이름의 float 형식 매트릭스는 MAT_SIZE * MAT_SIZE_2 의 크기를 가집니다. 실제 코드에서 인덱싱하는 컬럼 엘리먼트는 0~12 까지 총 13개입니다. 따라서 MAT_SIZE_2 을 13 으로 지정하면 충분합니다. 그런데 만약 이 값을 크게 한다면 어떤 현상이 발생할까요? 예를 들어 256 을 지정했다고 합시다. float 형식은 4 바이트 데이터를 가지지요. 따라서 a 매트릭스의 한 행은 1KB 를 차지하게 됩니다. 변수 i 가 하나씩 증가할 때마다 1KB 의 어드레스를 건너뛰는 셈이지요.
자, 그렇다면 a 매트릭스를 모두 L1 캐시에 밀어넣는다면 대략 MAT_SIZE 는 32 까지가 한계일 것입니다. (1KB * 32) 이제 이것을 응용하면, 외부에서 MAT_SIZE 변수를 계속 증가시켜서 30~35 사이에 정말 L1 캐시의 효과가 사라지는지를 관찰할 수 있겠지요.
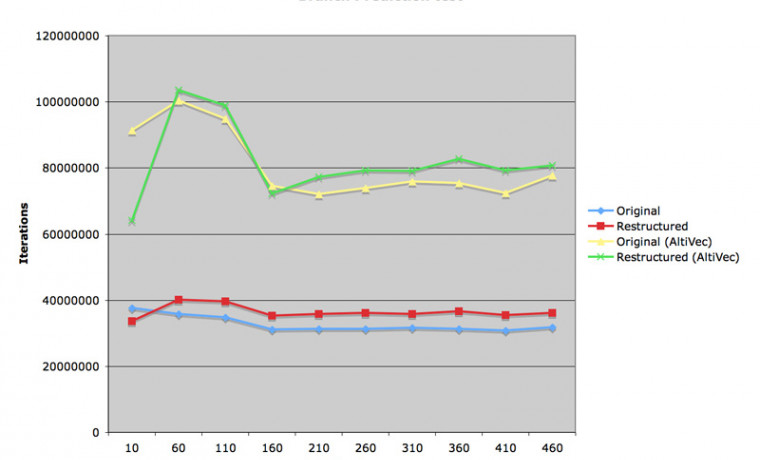
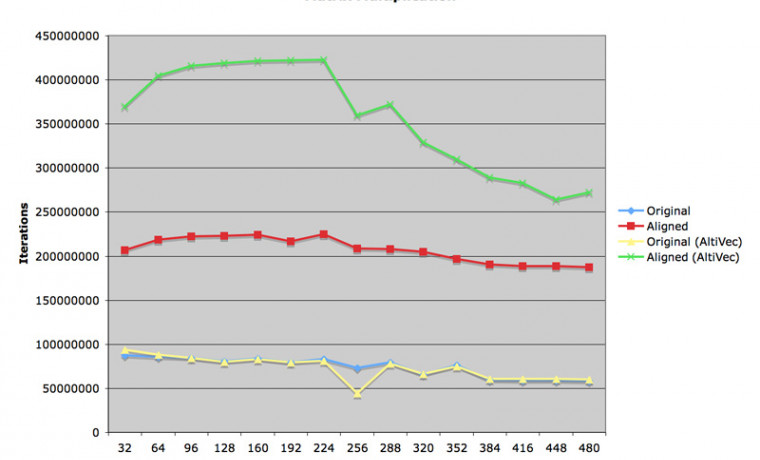
그래프를 하나 그려 보았습니다. X 축이 바로 문제의 MAT_SIZE 변수입니다. 정말로 30 에서 40 사이에서 계산량이 뚝 떨어지는 것을 관찰할 수 있습니다. 절벽처럼 뚝 떨어지지 않는 것은 그나마 L1 캐시 내에서 데이터를 처리하는 비율이 그나마 많이 있기 때문입니다. 하지만 64 를 넘어서게 되면 매번 iteration 마다 캐시가 깨어져서 결국 L1 캐시의 효과를 거둘 수 없게 됩니다.
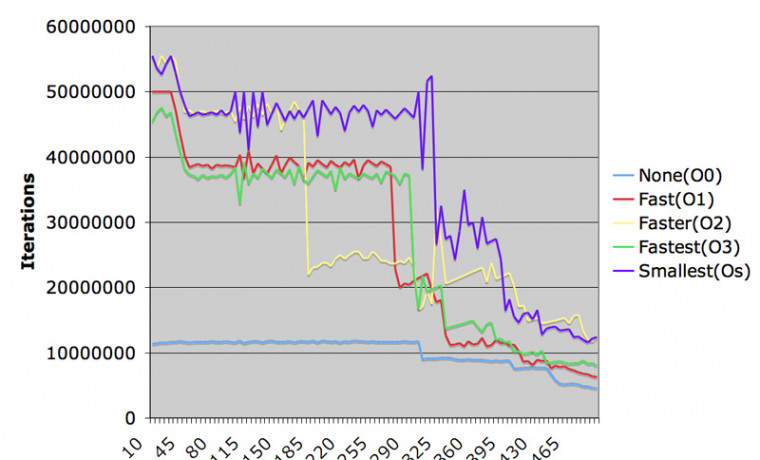
L2 캐시의 경우는 컴파일러 플래그에 따라서 큰 차이를 볼 수 있었습니다. 일단 None (O0) 의 경우에는 매트릭스 그나마 L1 캐시마저 효과를 거두지 못했습니다. 그리고 L2 캐시는 약 300KB 수준에서 깨어졌습니다.
한 단계를 올리면 (O1) 그럭저럭한 L1 캐시의 최고 속도를 나타내었지만, 280KB 에서 L2 캐시가 깨졌습니다. 코드 블럭의 크기가 O0 보다 늘어났다는 뜻이 되겠지요.
O2 플래그는 일반적으로 -fast 플래그를 설정하면 선택되는 기본값이지요. L1 캐시에서 최대값을 볼 수 있었지만 L2 캐시는 200KB 가 채 되기 전에 깨어지고 말았습니다. 컴파일된 코드가 빠른 속도로 동작하는 것까지는 좋았는데 코드 블럭이 더 크게 늘어나서 L2 캐시를 차지하고 있다는 뜻으로 풀이됩니다.
가장 빠르다는 O3 플래그의 경우는 오히려 속도가 떨어졌습니다. 컴파일러의 최적화가 항상 최적의 속도를 나타내지는 않는다는 것은 우리가 경험적으로 알고 있는 이야기이지요. 실제로 이런 그래프를 보게 되니 더 실감이 나는군요.
Smallest (OS) 플래그는 Mac OS X 를 컴파일할 때 쓰인 최적화 플래그입니다. 개발자 포럼에서 보면 어떤 분들은 "OS X 를 왜 O3 로 컴파일하지 않고 Os 로 컴파일했는가? 일부러 속도를 포기할 필요가 있었는가?" 라는 의견을 심심치 않게 봅니다. 이 실험에서는 가장 좋은 결과를 내었습니다. L1 캐시 내에서도 최고 속도를 기록했고, 코드 블럭이 간략해진 덕에 L2 캐시가 넉넉하게 버텨주었던 것 같습니다.
일단은 캐시가 정말로 동작을 하고 있다는 것을 눈으로 확인했습니다. 되도록이면 L1 캐시 내에서 연산을 끝마치도록 프로그램을 작성하는 것이 컴퓨터의 최대 속력을 끌어내는 방법이라는 것은 누구나 다 아는 이야기이겠지요. 앞으로 계속해서 몇 가지 경우를 상정해서 비슷한 실험을 계속 수행해 보도록 하겠습니다.
보유하고 계신 맥의 종류마다 약간씩 다르지만, 제가 가지고 있는 G5 프로세서는 64K/32K L1 캐시와 512K L2 캐시를 보유하고 있습니다. 그런데 실제로 이 캐시라는 놈이 얼마나 큰 역할을 하는지를 잘 경험해 보기는 쉽지 않지요. 그래서 먼저 캐시가 어떻게 작동하고 있는지를 확인해 보고자 짧은 프로그램을 작성해 보았습니다.
과학 계산 프로그램이건 토토샵이건 간에 그 내용은 모두 다 매트릭스 연산이라고 해도 과언이 아닙니다. 간단한 매트릭스 연산 예제를 한 번 작성해 보았습니다.
for( i = 0 ; i < MAT_SIZE ; i++ ) {
a[ i * MAT_SIZE_2 + 0 ] =
1.0 * a[ i * MAT_SIZE_2 + 12 ] + 2.0 * a[ i * MAT_SIZE_2 + 11 ] +
3.0 * a[ i * MAT_SIZE_2 + 10 ] + 4.0 * a[ i * MAT_SIZE_2 + 9 ] +
5.0 * a[ i * MAT_SIZE_2 + 8 ] + 6.0 * a[ i * MAT_SIZE_2 + 7 ] +
7.0 * a[ i * MAT_SIZE_2 + 6 ] + 8.0 * a[ i * MAT_SIZE_2 + 5 ] +
9.0 * ( a[ i * MAT_SIZE_2 + 4 ] + a[ i * MAT_SIZE_2 + 3 ] + a[ i * MAT_SIZE_2 + 2 ] ) ;
}
여기서 a 라는 이름의 float 형식 매트릭스는 MAT_SIZE * MAT_SIZE_2 의 크기를 가집니다. 실제 코드에서 인덱싱하는 컬럼 엘리먼트는 0~12 까지 총 13개입니다. 따라서 MAT_SIZE_2 을 13 으로 지정하면 충분합니다. 그런데 만약 이 값을 크게 한다면 어떤 현상이 발생할까요? 예를 들어 256 을 지정했다고 합시다. float 형식은 4 바이트 데이터를 가지지요. 따라서 a 매트릭스의 한 행은 1KB 를 차지하게 됩니다. 변수 i 가 하나씩 증가할 때마다 1KB 의 어드레스를 건너뛰는 셈이지요.
자, 그렇다면 a 매트릭스를 모두 L1 캐시에 밀어넣는다면 대략 MAT_SIZE 는 32 까지가 한계일 것입니다. (1KB * 32) 이제 이것을 응용하면, 외부에서 MAT_SIZE 변수를 계속 증가시켜서 30~35 사이에 정말 L1 캐시의 효과가 사라지는지를 관찰할 수 있겠지요.
그래프를 하나 그려 보았습니다. X 축이 바로 문제의 MAT_SIZE 변수입니다. 정말로 30 에서 40 사이에서 계산량이 뚝 떨어지는 것을 관찰할 수 있습니다. 절벽처럼 뚝 떨어지지 않는 것은 그나마 L1 캐시 내에서 데이터를 처리하는 비율이 그나마 많이 있기 때문입니다. 하지만 64 를 넘어서게 되면 매번 iteration 마다 캐시가 깨어져서 결국 L1 캐시의 효과를 거둘 수 없게 됩니다.
L2 캐시의 경우는 컴파일러 플래그에 따라서 큰 차이를 볼 수 있었습니다. 일단 None (O0) 의 경우에는 매트릭스 그나마 L1 캐시마저 효과를 거두지 못했습니다. 그리고 L2 캐시는 약 300KB 수준에서 깨어졌습니다.
한 단계를 올리면 (O1) 그럭저럭한 L1 캐시의 최고 속도를 나타내었지만, 280KB 에서 L2 캐시가 깨졌습니다. 코드 블럭의 크기가 O0 보다 늘어났다는 뜻이 되겠지요.
O2 플래그는 일반적으로 -fast 플래그를 설정하면 선택되는 기본값이지요. L1 캐시에서 최대값을 볼 수 있었지만 L2 캐시는 200KB 가 채 되기 전에 깨어지고 말았습니다. 컴파일된 코드가 빠른 속도로 동작하는 것까지는 좋았는데 코드 블럭이 더 크게 늘어나서 L2 캐시를 차지하고 있다는 뜻으로 풀이됩니다.
가장 빠르다는 O3 플래그의 경우는 오히려 속도가 떨어졌습니다. 컴파일러의 최적화가 항상 최적의 속도를 나타내지는 않는다는 것은 우리가 경험적으로 알고 있는 이야기이지요. 실제로 이런 그래프를 보게 되니 더 실감이 나는군요.
Smallest (OS) 플래그는 Mac OS X 를 컴파일할 때 쓰인 최적화 플래그입니다. 개발자 포럼에서 보면 어떤 분들은 "OS X 를 왜 O3 로 컴파일하지 않고 Os 로 컴파일했는가? 일부러 속도를 포기할 필요가 있었는가?" 라는 의견을 심심치 않게 봅니다. 이 실험에서는 가장 좋은 결과를 내었습니다. L1 캐시 내에서도 최고 속도를 기록했고, 코드 블럭이 간략해진 덕에 L2 캐시가 넉넉하게 버텨주었던 것 같습니다.
일단은 캐시가 정말로 동작을 하고 있다는 것을 눈으로 확인했습니다. 되도록이면 L1 캐시 내에서 연산을 끝마치도록 프로그램을 작성하는 것이 컴퓨터의 최대 속력을 끌어내는 방법이라는 것은 누구나 다 아는 이야기이겠지요. 앞으로 계속해서 몇 가지 경우를 상정해서 비슷한 실험을 계속 수행해 보도록 하겠습니다.
0
0
로그인 후 추천 또는 비추천하실 수 있습니다.
최신글이 없습니다.
최신글이 없습니다.










댓글목록 0