




[App 개발] 코드 최적화 (2) 컴파일러
hongjuny
141.♡.101.141
2005.08.13 06:13
1,129
1
0
0
본문
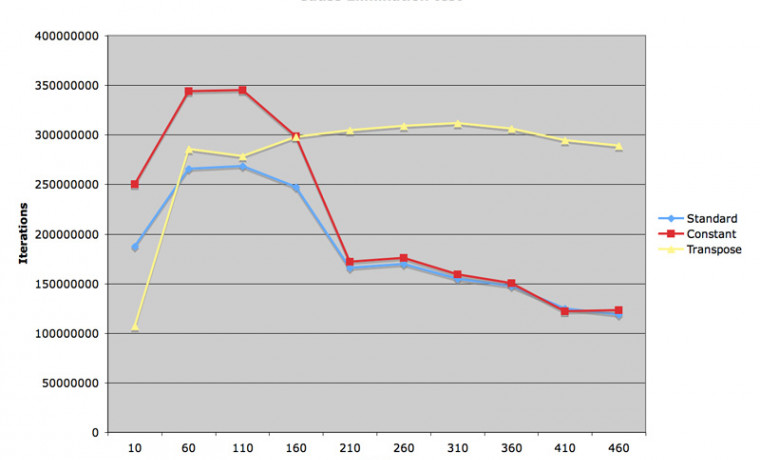
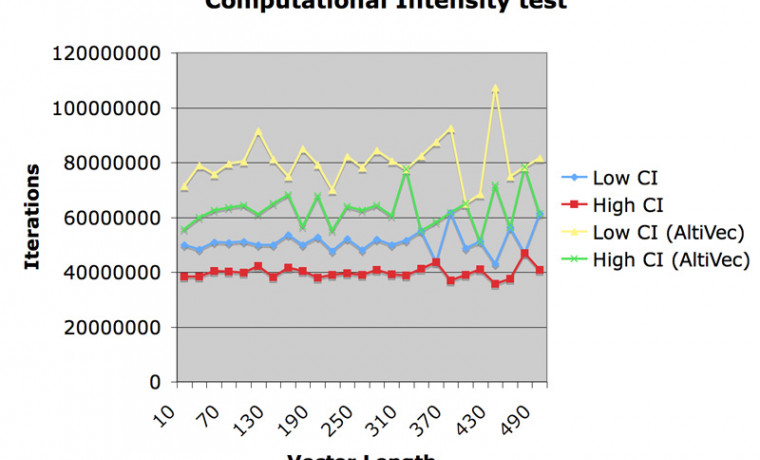
계산 밀도 (Computational Intensity)??라는 것이 있답니다. 이것이 무엇이냐 하면 컴퓨터에서 어떤 계산을 수행할 때 계산 명령 (Operation) 대 계산 인수 (Operand) 의 비율을 말합니다. 비싼 값을 주고 사는 좋은 컴파일러들은 대부분 이 값이 높으면 더 좋은 연산 능력을 기록한다고 합니다.
수식 1:
for( i = 0 ; i < MAT_SIZE ; i++ ) {
t1 = a[ k1 * MAT_SIZE_2 + i ] ;
t2 = a[ k2 * MAT_SIZE_2 + i ] ;
t3 = a[ k3 * MAT_SIZE_2 + i ] ;
t4 = a[ k4 * MAT_SIZE_2 + i ] ;
t5 = a[ k5 * MAT_SIZE_2 + i ] ;
t6 = a[ k6 * MAT_SIZE_2 + i ] ;
t7 = a[ k7 * MAT_SIZE_2 + i ] ;
t8 = a[ k8 * MAT_SIZE_2 + i ] ;
b1 = b[ k1 * MAT_SIZE_2 + i ] ;
b2 = b[ k2 * MAT_SIZE_2 + i ] ;
b3 = b[ k3 * MAT_SIZE_2 + i ] ;
b4 = b[ k4 * MAT_SIZE_2 + i ] ;
r1 = t5 * c1 + t7 * c2 ;
s1 = t6 * c1 - t8 * c2 ;
rs = t1 + r1 ;
ss = t2 + s1 ;
ru = t3 - r1 ;
su = t4 - s1 ;
b[ k1 * MAT_SIZE_2 + i ] = b1 + rs ;
b[ k2 * MAT_SIZE_2 + i ] = b2 + ru ;
b[ k3 * MAT_SIZE_2 + i ] = b3 + ss ;
b[ k4 * MAT_SIZE_2 + i ] = b4 - su ;
}
수식 2:
for( i = 0 ; i < MAT_SIZE ; i++ ) {
b[ k1 * MAT_SIZE_2 + i ] = b[ k1 * MAT_SIZE_2 + i ] + a[ k1 * MAT_SIZE_2 + i ] +
( a[ k5 * MAT_SIZE_2 + i ] * c1 + a[ k7 * MAT_SIZE_2 + i ] * c2 ) ;
b[ k2 * MAT_SIZE_2 + i ] = b[ k2 * MAT_SIZE_2 + i ] + a[ k2 * MAT_SIZE_2 + i ] +
( a[ k5 * MAT_SIZE_2 + i ] * c1 + a[ k7 * MAT_SIZE_2 + i ] * c2 ) ;
b[ k3 * MAT_SIZE_2 + i ] = b[ k3 * MAT_SIZE_2 + i ] + a[ k3 * MAT_SIZE_2 + i ] +
( a[ k6 * MAT_SIZE_2 + i ] * c1 - a[ k8 * MAT_SIZE_2 + i ] * c2 ) ;
b[ k4 * MAT_SIZE_2 + i ] = b[ k4 * MAT_SIZE_2 + i ] - a[ k4 * MAT_SIZE_2 + i ] +
( a[ k6 * MAT_SIZE_2 + i ] * c1 - b[ k8 * MAT_SIZE_2 + i ] * c2 ) ;
}
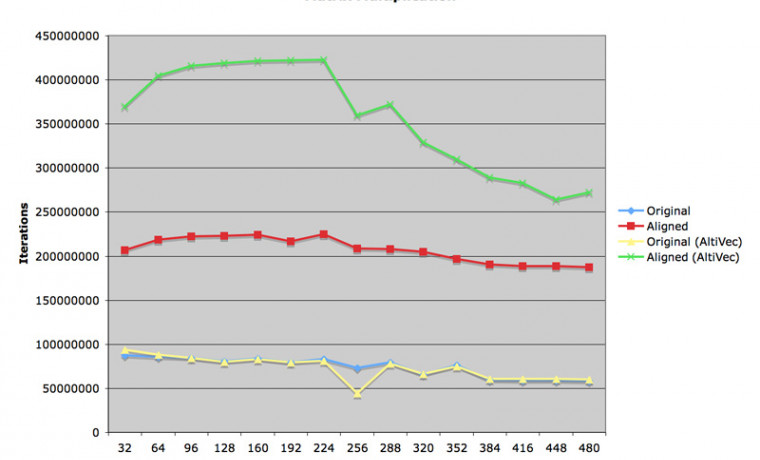
수식 1 과 수식 2 는 모두 동일한 복소수 매트릭스 연산 루틴입니다. 첫 번째 소스에서는 중간값을 변수에 기록해 가면서 작성한 프로그램이고, 두 번째 소스는 불필요한 오퍼랜드를 모두 삭제한 계산 밀도가 높은 소스입니다. 이론적으로는 두 번째 코드의 속도가 더 높아야 합니다만, 과연 OS X 에서도 그러한가?
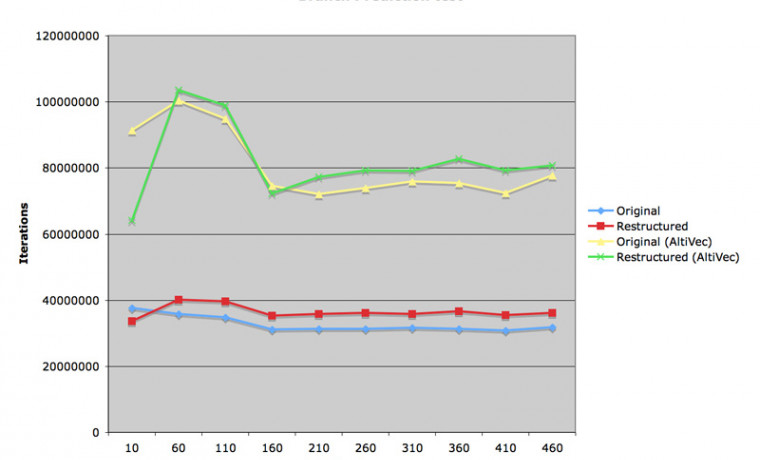
첫 번째 첨부그림을 보시면 예상 외로 수식 1 이 더 수행속도가 높은 것으로 나타났습니다. 일부러 열심히 계산 밀도를 높여서 간략화시킨 코드의 속도가 더 늦는다는 것은 이렇게 실제 확인해 보지 않으면 잘 모를 일이겠지요. 교과서만 보고 공부해온 사람들은 알기 힘든 내용일 것입니다.
애플에서는 Velocity Engine 이라고 하고, 모토롤라에서는 AltiVec 이라고 하는 SIMD 유닛을 이용한 컴파일 결과는 대략 30~40% 정도 속도 향상이라는 꽤 고무적인 성적이었습니다. gcc 4.0 에 새로 추가된 이 기능은 평상시에는 별 쓸모가 없는데, 이렇게 배열과 상수를 연속적으로 곱하는 루틴이 등장하면 큰 힘을 발휘하기 시작합니다.
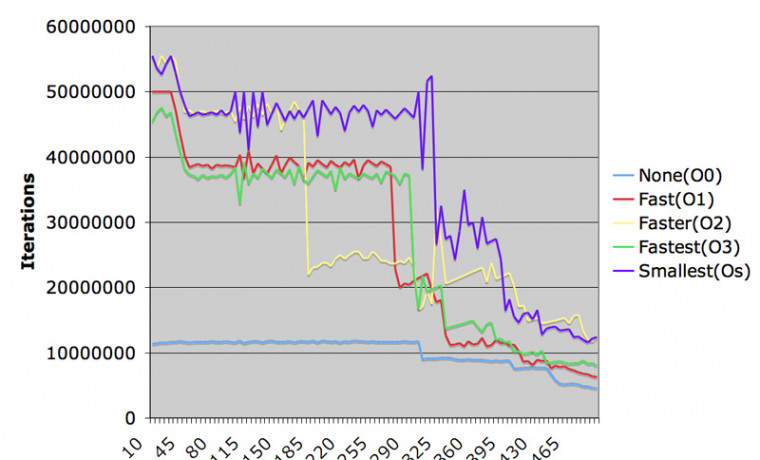
인텔 Xeon 3.2GHz 컴퓨터에서도 동일한 프로그램을 수행해 보았습니다. AltiVec 을 사용하지 않은 1.8GHz G5 보다는 약간 속도가 빨랐지만, AltiVec 을 적용한 기록에는 미치지 못했습니다. 매우 특이한 사실 한 가지는, 계산 밀도가 높은 루틴을 컴파일한 결과가 어떤 지점에서 뚝 떨어지는 것을 볼 수 있습니다. 이 지점은 공교롭게도 매트릭스 두 개의 크기가 모두 Xeon 의 L1 캐시 크기인 8KB 를 넘기는 부분이었습니다. 하지만 매트릭스가 아주 큰 경우에는 이런 일이 발생하지 않았고, 매우 미묘한 부분에서 이런 기가막힌 속도 저하가 관찰되었습니다. 추측컨대 프로세서에서 계속 L1 캐시와??L2 캐시의 데이터 교환이 일어나는 것이 아닌가 생각합니다. Xeon 프로세서의 버그이지요.
수식 1:
for( i = 0 ; i < MAT_SIZE ; i++ ) {
t1 = a[ k1 * MAT_SIZE_2 + i ] ;
t2 = a[ k2 * MAT_SIZE_2 + i ] ;
t3 = a[ k3 * MAT_SIZE_2 + i ] ;
t4 = a[ k4 * MAT_SIZE_2 + i ] ;
t5 = a[ k5 * MAT_SIZE_2 + i ] ;
t6 = a[ k6 * MAT_SIZE_2 + i ] ;
t7 = a[ k7 * MAT_SIZE_2 + i ] ;
t8 = a[ k8 * MAT_SIZE_2 + i ] ;
b1 = b[ k1 * MAT_SIZE_2 + i ] ;
b2 = b[ k2 * MAT_SIZE_2 + i ] ;
b3 = b[ k3 * MAT_SIZE_2 + i ] ;
b4 = b[ k4 * MAT_SIZE_2 + i ] ;
r1 = t5 * c1 + t7 * c2 ;
s1 = t6 * c1 - t8 * c2 ;
rs = t1 + r1 ;
ss = t2 + s1 ;
ru = t3 - r1 ;
su = t4 - s1 ;
b[ k1 * MAT_SIZE_2 + i ] = b1 + rs ;
b[ k2 * MAT_SIZE_2 + i ] = b2 + ru ;
b[ k3 * MAT_SIZE_2 + i ] = b3 + ss ;
b[ k4 * MAT_SIZE_2 + i ] = b4 - su ;
}
수식 2:
for( i = 0 ; i < MAT_SIZE ; i++ ) {
b[ k1 * MAT_SIZE_2 + i ] = b[ k1 * MAT_SIZE_2 + i ] + a[ k1 * MAT_SIZE_2 + i ] +
( a[ k5 * MAT_SIZE_2 + i ] * c1 + a[ k7 * MAT_SIZE_2 + i ] * c2 ) ;
b[ k2 * MAT_SIZE_2 + i ] = b[ k2 * MAT_SIZE_2 + i ] + a[ k2 * MAT_SIZE_2 + i ] +
( a[ k5 * MAT_SIZE_2 + i ] * c1 + a[ k7 * MAT_SIZE_2 + i ] * c2 ) ;
b[ k3 * MAT_SIZE_2 + i ] = b[ k3 * MAT_SIZE_2 + i ] + a[ k3 * MAT_SIZE_2 + i ] +
( a[ k6 * MAT_SIZE_2 + i ] * c1 - a[ k8 * MAT_SIZE_2 + i ] * c2 ) ;
b[ k4 * MAT_SIZE_2 + i ] = b[ k4 * MAT_SIZE_2 + i ] - a[ k4 * MAT_SIZE_2 + i ] +
( a[ k6 * MAT_SIZE_2 + i ] * c1 - b[ k8 * MAT_SIZE_2 + i ] * c2 ) ;
}
수식 1 과 수식 2 는 모두 동일한 복소수 매트릭스 연산 루틴입니다. 첫 번째 소스에서는 중간값을 변수에 기록해 가면서 작성한 프로그램이고, 두 번째 소스는 불필요한 오퍼랜드를 모두 삭제한 계산 밀도가 높은 소스입니다. 이론적으로는 두 번째 코드의 속도가 더 높아야 합니다만, 과연 OS X 에서도 그러한가?
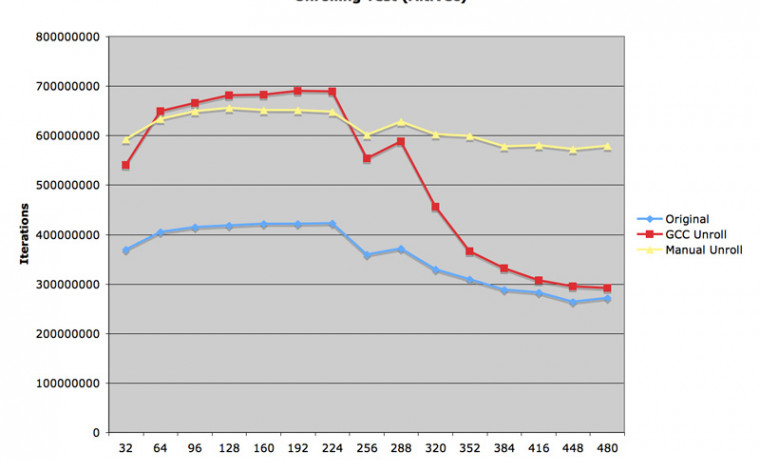
첫 번째 첨부그림을 보시면 예상 외로 수식 1 이 더 수행속도가 높은 것으로 나타났습니다. 일부러 열심히 계산 밀도를 높여서 간략화시킨 코드의 속도가 더 늦는다는 것은 이렇게 실제 확인해 보지 않으면 잘 모를 일이겠지요. 교과서만 보고 공부해온 사람들은 알기 힘든 내용일 것입니다.
애플에서는 Velocity Engine 이라고 하고, 모토롤라에서는 AltiVec 이라고 하는 SIMD 유닛을 이용한 컴파일 결과는 대략 30~40% 정도 속도 향상이라는 꽤 고무적인 성적이었습니다. gcc 4.0 에 새로 추가된 이 기능은 평상시에는 별 쓸모가 없는데, 이렇게 배열과 상수를 연속적으로 곱하는 루틴이 등장하면 큰 힘을 발휘하기 시작합니다.
인텔 Xeon 3.2GHz 컴퓨터에서도 동일한 프로그램을 수행해 보았습니다. AltiVec 을 사용하지 않은 1.8GHz G5 보다는 약간 속도가 빨랐지만, AltiVec 을 적용한 기록에는 미치지 못했습니다. 매우 특이한 사실 한 가지는, 계산 밀도가 높은 루틴을 컴파일한 결과가 어떤 지점에서 뚝 떨어지는 것을 볼 수 있습니다. 이 지점은 공교롭게도 매트릭스 두 개의 크기가 모두 Xeon 의 L1 캐시 크기인 8KB 를 넘기는 부분이었습니다. 하지만 매트릭스가 아주 큰 경우에는 이런 일이 발생하지 않았고, 매우 미묘한 부분에서 이런 기가막힌 속도 저하가 관찰되었습니다. 추측컨대 프로세서에서 계속 L1 캐시와??L2 캐시의 데이터 교환이 일어나는 것이 아닌가 생각합니다. Xeon 프로세서의 버그이지요.
0
0
로그인 후 추천 또는 비추천하실 수 있습니다.
최신글이 없습니다.
최신글이 없습니다.










댓글목록 1
doyub님의 댓글
- doyub님의 홈
- 전체게시물
- 아이디로 검색
210.♡.56.90 2005.08.14 12:32잘 보고 가요~
항상 좋은 정보 감사드립니다^^