




[App 개발] 코드 최적화 (3) 인덱싱
hongjuny
151.♡.116.35
2005.08.13 19:20
1,117
0
0
0
본문
매트릭스 연산은 여러 곳에서 널리 쓰이고 있습니다. 단순 반복적인 계산을 거듭하는 이 루틴의 효율을 어떻게 높이느냐에 따라서 컴퓨터의 최대 계산 능력을 끌어낼 수도, 혹은 전혀 이용하지 못할 수도 있습니다.
다음의 예제는 가우스 소거법 소스를 간단히 표현한 것입니다.
for( i = 0 ; i < MAT_SIZE ; i++ ) {
a[ i * MAT_SIZE + i ] = 1.0 / a[ i * MAT_SIZE + i ] ;
for( j = i + 1 ; j < MAT_SIZE ; j++ ) {
a[ i * MAT_SIZE + j ] *= a[ i * MAT_SIZE + i ] ;
for( k = i + 1 ; k < MAT_SIZE ; k++ ) {
a[ k * MAT_SIZE + j ] -= a[ i * MAT_SIZE + j ] * a[ k * MAT_SIZE + i ] ;
}
}
}
컴퓨터 공학을 하시는 분들의 표현을 빌어 쓴다면 이 루틴은 O(n^3) 이라고 할 수 있나요? a 매트릭스의 내용을 세 번 훑어 내려가게 되는데, 실제로는 대략 (n^3)/2 번의 연산이 이루어지는 가장 안쪽의 수식을 효율적으로 만드는 것이 속도 향상의 열쇠라고 할 수 있겠습니다.
먼저, 가장 안쪽의 루프는 변수 k 의 값이 변화되는 구문입니다. a[ i * MAT_SIZE + j ] 는 k 루프 내에서는 값이 변하지 않는 상수이지요. 컴파일러에서 알아서 이런 것을 상수로 간주해서 a 매트릭스 인덱싱을 하지 않으면 참 좋으련만, 실제로 해본 결과 그것을 컴파일러에서 해 주지는 않는 것 같습니다.
for( i = 0 ; i < MAT_SIZE ; i++ ) {
a[ i * MAT_SIZE + i ] = 1.0 / a[ i * MAT_SIZE + i ] ;
for( j = i + 1 ; j < MAT_SIZE ; j++ ) {
a[ i * MAT_SIZE + j ] *= a[ i * MAT_SIZE + i ] ;
t1 = a[ i * MAT_SIZE + j ] ;
for( k = i + 1 ; k < MAT_SIZE ; k++ ) {
a[ k * MAT_SIZE + j ] -= t1 * a[ k * MAT_SIZE + i ] ;
}
}
}
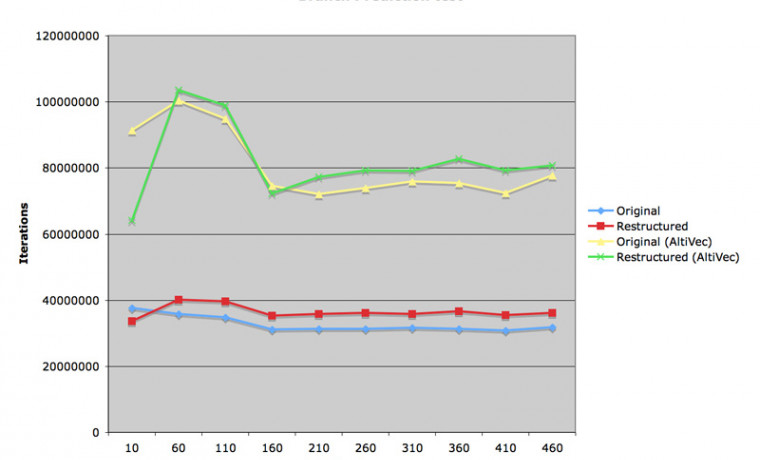
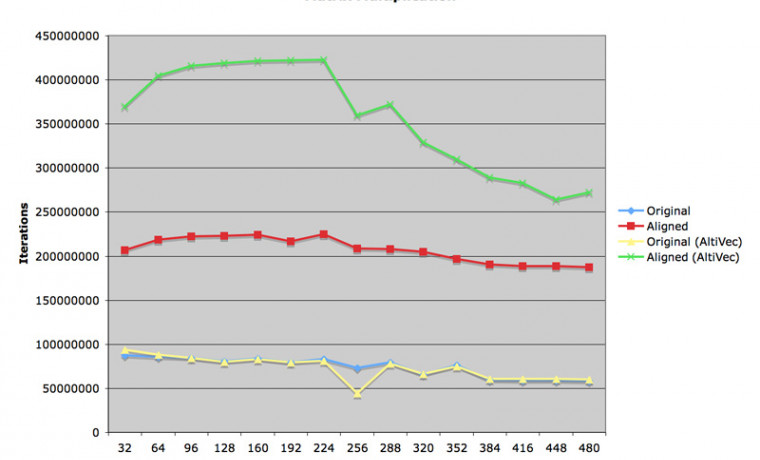
이렇게 간이 변수 t1 을 설정해서 루프 k 의 인덱싱을 하나 줄이는 것만으로도 실행 속도를 많이 높일 수 있었습니다. 그러나, 첫 번째 그림에서 보시는 대로, a 매트릭스의 크기가 커지면 커질수록 결국 첫 번째 소스와 두 번째 소스의 결과가 동일해지는 것을 보게 됩니다. 왜냐하면 이 때부터는 L2 캐시가 깨어져서 이 루틴의 병목 현상이 상수 치환이 아니라 a[ k * MAT_SIZE + i ] 의 인덱싱에 문제가 발생했기 때문입니다. k 값이 증가할 때마다 a 매트릭스 내용의 인덱스는 k * MAT_SIZE 만큼 증가합니다. MAT_SIZE 가 커지게 되면 k 루프 내에서 L2 캐시 바깥의 내용을 참조하는 비율이 점점 더 높아지게 되고, 그래서 프로그램 수행을 위해서 속도가 느린 메인 메모리의 내용을 계속 끌어와야 한다는 이야기가 됩니다. 메모리 버스의 속도가 느린 G4 프로세서에서는 훨씬 더 치명적인 결과가 됩니다.
transpose( a ) ;
for( i = 0 ; i < MAT_SIZE ; i++ ) {
a[ i * MAT_SIZE + i ] = 1.0 / a[ i * MAT_SIZE + i ] ;
for( j = i + 1 ; j < MAT_SIZE ; j++ ) {
a[ j * MAT_SIZE + i ] *= a[ i * MAT_SIZE + i ] ;
t1 = a[ j * MAT_SIZE + i ] ;
for( k = i + 1 ; k < MAT_SIZE ; k++ ) {
a[ j * MAT_SIZE + k ] -= t1 * a[ i * MAT_SIZE + k ] ;
}
}
}
transpose( a ) ;
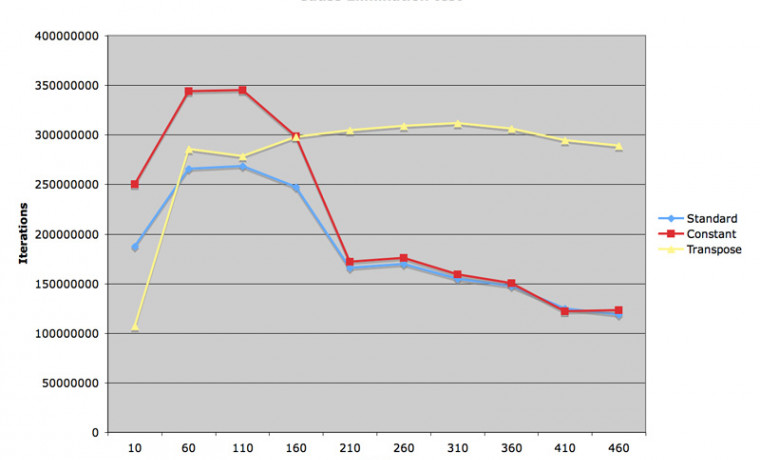
세 번째 루틴은 a 매트릭스의 transpose 를 구하여 내부 k 루프의 인덱스가 k * MAT_SIZE 대신 k 만큼 증가하게 만들었습니다. 여기서는 1 씩 증가하게 되겠지요. 이렇게 되면 L2 캐시가 깨어지는 비율을 줄일 수 있게 되어 덩치가 큰 a 매트릭스 연산의 효율을 획기적으로 증가시킬 수 있습니다.
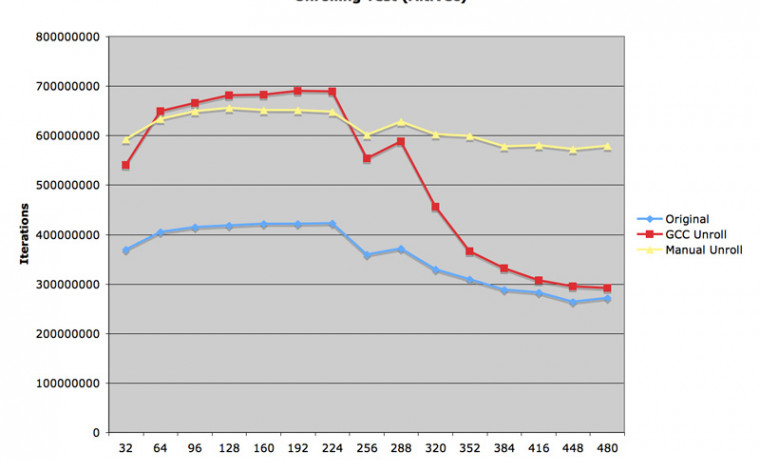
첫 번째 그림에서 보시면, 매트릭스 크기가 10 x 10 일 경우에는 매트릭스 내용이 모두 L1 캐시에 탑재되어 있으므로 두 번의 transpose 를 취해야 하는 세 번째 루틴의 속도가 가장 느린 결과를 얻었습니다. 그러나 매트릭스 크기가 증가하면 증가할 수록 세 번째 소스의 효율이 증대되고, 210 x 210 이상의 매트릭스에서는 압도적으로 빠른 속력을 갖게 됩니다.
두 번째 그림은 AltiVec 을 적용한 결과입니다. 60% 이상의 고무적인 속도 향상을 관찰할 수 있었고, 세 번째 루틴은 최대 속력 1 GFlops 이상의 능력을 발휘하였습니다.
다음의 예제는 가우스 소거법 소스를 간단히 표현한 것입니다.
for( i = 0 ; i < MAT_SIZE ; i++ ) {
a[ i * MAT_SIZE + i ] = 1.0 / a[ i * MAT_SIZE + i ] ;
for( j = i + 1 ; j < MAT_SIZE ; j++ ) {
a[ i * MAT_SIZE + j ] *= a[ i * MAT_SIZE + i ] ;
for( k = i + 1 ; k < MAT_SIZE ; k++ ) {
a[ k * MAT_SIZE + j ] -= a[ i * MAT_SIZE + j ] * a[ k * MAT_SIZE + i ] ;
}
}
}
컴퓨터 공학을 하시는 분들의 표현을 빌어 쓴다면 이 루틴은 O(n^3) 이라고 할 수 있나요? a 매트릭스의 내용을 세 번 훑어 내려가게 되는데, 실제로는 대략 (n^3)/2 번의 연산이 이루어지는 가장 안쪽의 수식을 효율적으로 만드는 것이 속도 향상의 열쇠라고 할 수 있겠습니다.
먼저, 가장 안쪽의 루프는 변수 k 의 값이 변화되는 구문입니다. a[ i * MAT_SIZE + j ] 는 k 루프 내에서는 값이 변하지 않는 상수이지요. 컴파일러에서 알아서 이런 것을 상수로 간주해서 a 매트릭스 인덱싱을 하지 않으면 참 좋으련만, 실제로 해본 결과 그것을 컴파일러에서 해 주지는 않는 것 같습니다.
for( i = 0 ; i < MAT_SIZE ; i++ ) {
a[ i * MAT_SIZE + i ] = 1.0 / a[ i * MAT_SIZE + i ] ;
for( j = i + 1 ; j < MAT_SIZE ; j++ ) {
a[ i * MAT_SIZE + j ] *= a[ i * MAT_SIZE + i ] ;
t1 = a[ i * MAT_SIZE + j ] ;
for( k = i + 1 ; k < MAT_SIZE ; k++ ) {
a[ k * MAT_SIZE + j ] -= t1 * a[ k * MAT_SIZE + i ] ;
}
}
}
이렇게 간이 변수 t1 을 설정해서 루프 k 의 인덱싱을 하나 줄이는 것만으로도 실행 속도를 많이 높일 수 있었습니다. 그러나, 첫 번째 그림에서 보시는 대로, a 매트릭스의 크기가 커지면 커질수록 결국 첫 번째 소스와 두 번째 소스의 결과가 동일해지는 것을 보게 됩니다. 왜냐하면 이 때부터는 L2 캐시가 깨어져서 이 루틴의 병목 현상이 상수 치환이 아니라 a[ k * MAT_SIZE + i ] 의 인덱싱에 문제가 발생했기 때문입니다. k 값이 증가할 때마다 a 매트릭스 내용의 인덱스는 k * MAT_SIZE 만큼 증가합니다. MAT_SIZE 가 커지게 되면 k 루프 내에서 L2 캐시 바깥의 내용을 참조하는 비율이 점점 더 높아지게 되고, 그래서 프로그램 수행을 위해서 속도가 느린 메인 메모리의 내용을 계속 끌어와야 한다는 이야기가 됩니다. 메모리 버스의 속도가 느린 G4 프로세서에서는 훨씬 더 치명적인 결과가 됩니다.
transpose( a ) ;
for( i = 0 ; i < MAT_SIZE ; i++ ) {
a[ i * MAT_SIZE + i ] = 1.0 / a[ i * MAT_SIZE + i ] ;
for( j = i + 1 ; j < MAT_SIZE ; j++ ) {
a[ j * MAT_SIZE + i ] *= a[ i * MAT_SIZE + i ] ;
t1 = a[ j * MAT_SIZE + i ] ;
for( k = i + 1 ; k < MAT_SIZE ; k++ ) {
a[ j * MAT_SIZE + k ] -= t1 * a[ i * MAT_SIZE + k ] ;
}
}
}
transpose( a ) ;
세 번째 루틴은 a 매트릭스의 transpose 를 구하여 내부 k 루프의 인덱스가 k * MAT_SIZE 대신 k 만큼 증가하게 만들었습니다. 여기서는 1 씩 증가하게 되겠지요. 이렇게 되면 L2 캐시가 깨어지는 비율을 줄일 수 있게 되어 덩치가 큰 a 매트릭스 연산의 효율을 획기적으로 증가시킬 수 있습니다.
첫 번째 그림에서 보시면, 매트릭스 크기가 10 x 10 일 경우에는 매트릭스 내용이 모두 L1 캐시에 탑재되어 있으므로 두 번의 transpose 를 취해야 하는 세 번째 루틴의 속도가 가장 느린 결과를 얻었습니다. 그러나 매트릭스 크기가 증가하면 증가할 수록 세 번째 소스의 효율이 증대되고, 210 x 210 이상의 매트릭스에서는 압도적으로 빠른 속력을 갖게 됩니다.
두 번째 그림은 AltiVec 을 적용한 결과입니다. 60% 이상의 고무적인 속도 향상을 관찰할 수 있었고, 세 번째 루틴은 최대 속력 1 GFlops 이상의 능력을 발휘하였습니다.
0
0
로그인 후 추천 또는 비추천하실 수 있습니다.
최신글이 없습니다.
최신글이 없습니다.










댓글목록 0