




[App 개발] 코드 최적화 (4) 행렬, AltiVec
hongjuny
141.♡.105.17
2005.08.14 21:40
1,295
0
0
0
본문
이번에는 매우 고전적이면서 아직도 수없이 많은 곳에서 쓰이고 있는 행렬 곱셈 문제를 한 번 생각해 보겠습니다.
for( i = 0 ; i < MAT_SIZE ; i++ ) {
for( j = 0 ; j < MAT_SIZE ; j++ ) {
a[ j * MAT_SIZE + i ] = 0.0f ;
for( k = 0 ; k < MAT_SIZE ; k++ ) {
a[ j * MAT_SIZE + i ] += b[ k * MAT_SIZE + i ] * c[ j * MAT_SIZE + k ] ;
}
}
}
전형적인 행렬 계산 방법이지요. b 의 행과 c 의 열을 곱한 값을 모두 더하여 a 매트릭스에 집어넣는 아주 교과서적인 구현입니다. 지금까지 살펴본 것을 되짚어서 이 코드를 생각해 보시면, b 행렬의 증가분이 k 가 증가할 때마다 MAT_SIZE 만큼 증가함으로써 캐시가 깨어지는 현상이 더 빈번하게 일어날 수 있는 코드입니다. 따라서 이 코드를 다음과 같이 간단하게 재정렬해 보겠습니다.
for( j = 0 ; j < MAT_SIZE ; j++ ) {
for( i = 0 ; i < MAT_SIZE ; i++ ) {
a[ j * MAT_SIZE + i ] = 0.0f ;
}
}
for( k = 0 ; k < MAT_SIZE ; k++ ) {
for( j = 0 ; j < MAT_SIZE ; j++ ) {
t1 = c[ j * MAT_SIZE + k ] ;
for( i = 0 ; i < MAT_SIZE ; i++ ) {
a[ j * MAT_SIZE + i ] += b[ k * MAT_SIZE + i ] * t1 ;
}
}
}
먼저 a 행렬의 내용을 비웁니다. 그리고 인덱스 변수 중에서 i 를 안쪽에 넣음으로써 a 행렬과 b 행렬은 순차적으로 참조되게끔 하였습니다. 간이 변수 t1 은 i 인덱스 루프 내에서 상수값으로 간주합니다. 이 정도의 작업만으로도 상당히 좋은 결과를 얻어낼 수 있습니다.
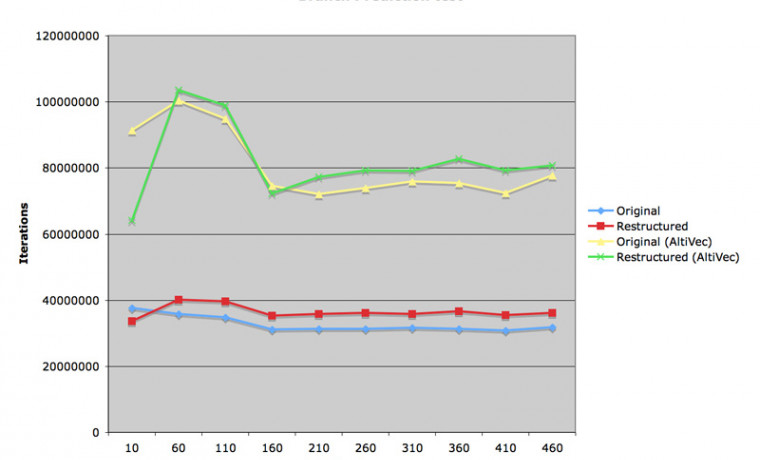
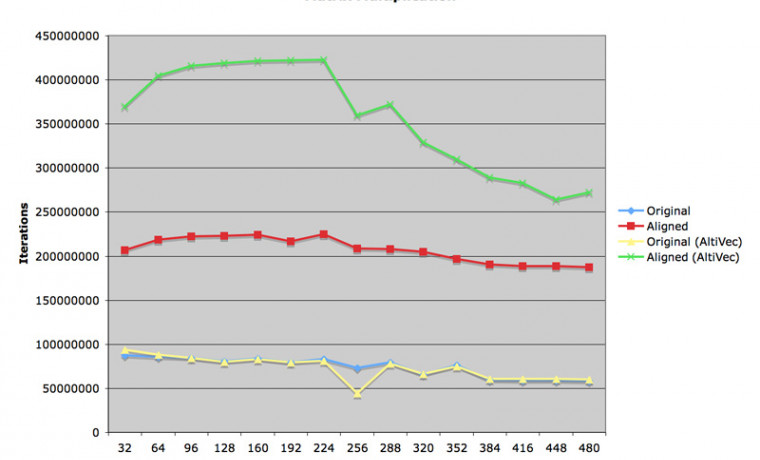
첨부 그림 첫 번째를 보시면, 재정렬된 코드는 기본 코드에서 두 배 이상의 속력을 내었습니다. Auto Vectorization 플래그를 On 으로 선택한 다음 수행한 실험에서는 기본 코드에서는 속도의 변화가 없었고, 재정렬된 코드는 또 다시 두 배 정도의 속도 향상을 관찰할 수 있습니다. 아주 약간의 프로그램 수정만으로 1.0 GFlops 의 성능을 획득할 수 있다면 꽤 남는 장사라고 할 수 있겠지요?
하지만 vDSP 가 출동하면 어떨까요? ㅡㅡ;;;
애플에서 제공하는 계산 라이브러리가 있습니다. 예전에는 vecLib 라는 이름으로 불리웠고, 지금은 Accelerate.Framework 로 제공되는 계산 라이브러리입니다. Xcode 에 예제도 제공되어 있으므로 자세한 내용은 참조하시고요.
여기서는 vDSP_mmul 함수를 출동시켜 보겠습니다. (ㅎㅎ) 이 루틴들은 AltiVec 으로 최고 속도를 낼 수 있도록 최적화되어 있습니다. 그래서 매트릭스 크기가 4의 배수가 되면 AltiVec 루틴이 가동되어 훨씬 더 빠른 속도를 기록하게 됩니다. (이번 실험에서 매트릭스 크기를 32 씩 증가시킨 이유가 이것 때문입니다.)
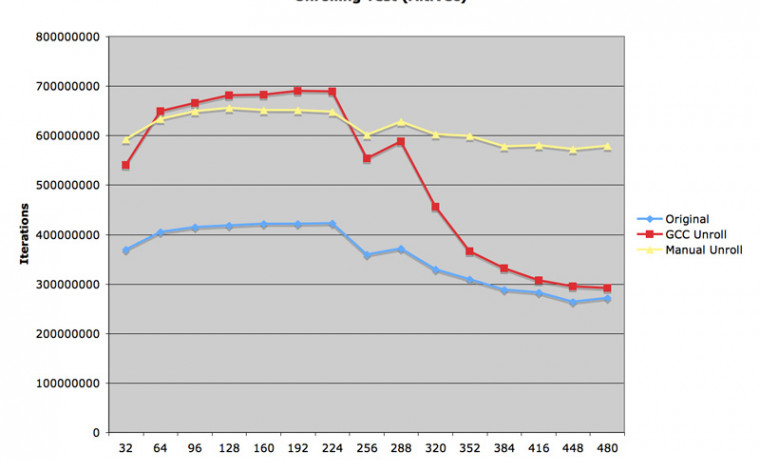
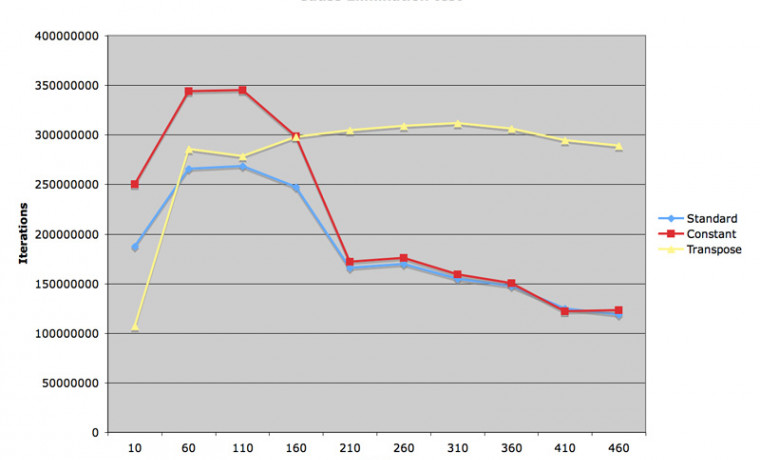
두 번째 그림을 보시면, L2 캐시 내에서의 처리는 대략 10 배를 넘는 성능을 발휘하였습니다. 캐시가 깨어지고 난 다음에는 성능이 반토막 났습니다만 그래도 예제에서 쓰인 재정렬된 코드보다 대략 8~9 배의 성능을 발휘하였습니다. 상당히 최적화에 공을 들인 라이브러리라고 할 수 있겠습니다. 그림으로는 제공하고 있지 않습니다만, 매트릭스 크기가 4의 배수가 아닐 경우 vDSP 함수는 AltiVec 루틴에 비해서 1/4 의 속도를 기록하였습니다. 네 개의 유닛이 모두 최대로 가동되고 있다는 뜻이지요.
향후 인텔맥이 출현했을 때 Acceleratie.Framework 에서도 SSE3 를 지원할 것이 거의 확실하므로 double precision 연산도 두 배의 성능을 낼 수 있을 것입니다.
자, 열심히 최적화한 코드가 애플이 제공하는 라이브러리보다 성능이 떨어진다고 해서 이 글이 전혀 쓸모없는 것은 아니지요? ㅎㅎㅎ 여기서 말씀드리고자 하는 것은, 아주 약간만 코딩에 신경 써 주신는 것으로도 상당히 높은 효율을 얻을 수 있다는 점이 큰 교훈이라고 할 수 있을 것입니다. 그리고 전형적인 계산 루틴에서 Accelerate.Framework 을 유용하게 쓸 수 있을 것입니다.
for( i = 0 ; i < MAT_SIZE ; i++ ) {
for( j = 0 ; j < MAT_SIZE ; j++ ) {
a[ j * MAT_SIZE + i ] = 0.0f ;
for( k = 0 ; k < MAT_SIZE ; k++ ) {
a[ j * MAT_SIZE + i ] += b[ k * MAT_SIZE + i ] * c[ j * MAT_SIZE + k ] ;
}
}
}
전형적인 행렬 계산 방법이지요. b 의 행과 c 의 열을 곱한 값을 모두 더하여 a 매트릭스에 집어넣는 아주 교과서적인 구현입니다. 지금까지 살펴본 것을 되짚어서 이 코드를 생각해 보시면, b 행렬의 증가분이 k 가 증가할 때마다 MAT_SIZE 만큼 증가함으로써 캐시가 깨어지는 현상이 더 빈번하게 일어날 수 있는 코드입니다. 따라서 이 코드를 다음과 같이 간단하게 재정렬해 보겠습니다.
for( j = 0 ; j < MAT_SIZE ; j++ ) {
for( i = 0 ; i < MAT_SIZE ; i++ ) {
a[ j * MAT_SIZE + i ] = 0.0f ;
}
}
for( k = 0 ; k < MAT_SIZE ; k++ ) {
for( j = 0 ; j < MAT_SIZE ; j++ ) {
t1 = c[ j * MAT_SIZE + k ] ;
for( i = 0 ; i < MAT_SIZE ; i++ ) {
a[ j * MAT_SIZE + i ] += b[ k * MAT_SIZE + i ] * t1 ;
}
}
}
먼저 a 행렬의 내용을 비웁니다. 그리고 인덱스 변수 중에서 i 를 안쪽에 넣음으로써 a 행렬과 b 행렬은 순차적으로 참조되게끔 하였습니다. 간이 변수 t1 은 i 인덱스 루프 내에서 상수값으로 간주합니다. 이 정도의 작업만으로도 상당히 좋은 결과를 얻어낼 수 있습니다.
첨부 그림 첫 번째를 보시면, 재정렬된 코드는 기본 코드에서 두 배 이상의 속력을 내었습니다. Auto Vectorization 플래그를 On 으로 선택한 다음 수행한 실험에서는 기본 코드에서는 속도의 변화가 없었고, 재정렬된 코드는 또 다시 두 배 정도의 속도 향상을 관찰할 수 있습니다. 아주 약간의 프로그램 수정만으로 1.0 GFlops 의 성능을 획득할 수 있다면 꽤 남는 장사라고 할 수 있겠지요?
하지만 vDSP 가 출동하면 어떨까요? ㅡㅡ;;;
애플에서 제공하는 계산 라이브러리가 있습니다. 예전에는 vecLib 라는 이름으로 불리웠고, 지금은 Accelerate.Framework 로 제공되는 계산 라이브러리입니다. Xcode 에 예제도 제공되어 있으므로 자세한 내용은 참조하시고요.
여기서는 vDSP_mmul 함수를 출동시켜 보겠습니다. (ㅎㅎ) 이 루틴들은 AltiVec 으로 최고 속도를 낼 수 있도록 최적화되어 있습니다. 그래서 매트릭스 크기가 4의 배수가 되면 AltiVec 루틴이 가동되어 훨씬 더 빠른 속도를 기록하게 됩니다. (이번 실험에서 매트릭스 크기를 32 씩 증가시킨 이유가 이것 때문입니다.)
두 번째 그림을 보시면, L2 캐시 내에서의 처리는 대략 10 배를 넘는 성능을 발휘하였습니다. 캐시가 깨어지고 난 다음에는 성능이 반토막 났습니다만 그래도 예제에서 쓰인 재정렬된 코드보다 대략 8~9 배의 성능을 발휘하였습니다. 상당히 최적화에 공을 들인 라이브러리라고 할 수 있겠습니다. 그림으로는 제공하고 있지 않습니다만, 매트릭스 크기가 4의 배수가 아닐 경우 vDSP 함수는 AltiVec 루틴에 비해서 1/4 의 속도를 기록하였습니다. 네 개의 유닛이 모두 최대로 가동되고 있다는 뜻이지요.
향후 인텔맥이 출현했을 때 Acceleratie.Framework 에서도 SSE3 를 지원할 것이 거의 확실하므로 double precision 연산도 두 배의 성능을 낼 수 있을 것입니다.
자, 열심히 최적화한 코드가 애플이 제공하는 라이브러리보다 성능이 떨어진다고 해서 이 글이 전혀 쓸모없는 것은 아니지요? ㅎㅎㅎ 여기서 말씀드리고자 하는 것은, 아주 약간만 코딩에 신경 써 주신는 것으로도 상당히 높은 효율을 얻을 수 있다는 점이 큰 교훈이라고 할 수 있을 것입니다. 그리고 전형적인 계산 루틴에서 Accelerate.Framework 을 유용하게 쓸 수 있을 것입니다.
0
0
로그인 후 추천 또는 비추천하실 수 있습니다.
최신글이 없습니다.
최신글이 없습니다.










댓글목록 0