




[App 개발] 코드 최적화 (5) Unrolling
hongjuny
151.♡.16.179
2005.08.15 10:18
1,167
0
0
0
본문
언롤링이라는 기법은 언뜻 보기에는 거의 삽질과 다름이 없습니다. 지난 (4) 번 예제에서 사용된 코드를 언롤링한 코드의 예를 보시면 이야기가 더 쉽게 진행될 것 같습니다.
for( j = 0 ; j < MAT_SIZE ; j++ ) {
for( i = 0 ; i < MAT_SIZE ; i++ ) {
a[ j * MAT_SIZE + i ] = 0.0f ;
}
}
for( k = 0 ; k < MAT_SIZE - 3 ; k+=4 ) {
for( j = 0 ; j < MAT_SIZE ; j++ ) {
t1 = c[ j * MAT_SIZE + k ] ;
t2 = c[ j * MAT_SIZE + k + 1 ] ;
t3 = c[ j * MAT_SIZE + k + 2 ] ;
t4 = c[ j * MAT_SIZE + k + 3 ] ;
for( i = 0 ; i < MAT_SIZE ; i++ ) {
a[ j * MAT_SIZE + i ] +=
b[ k * MAT_SIZE + i ] * t1 +
b[ ( k + 1 ) * MAT_SIZE + i ] * t2 +
b[ ( k + 2 ) * MAT_SIZE + i ] * t3 +
b[ ( k + 3 ) * MAT_SIZE + i ] * t4 ;
}
}
}
for( kk = k ; kk < MAT_SIZE ; kk++ ) {
for( j = 0 ; j < MAT_SIZE ; j++ ) {
t1 = c[ j * MAT_SIZE + kk ] ;
for( i = 0 ; i < MAT_SIZE ; i++ ) {
a[ j * MAT_SIZE + i ] += b[ kk * MAT_SIZE + i ] * t1 ;
}
}
}
보시면 계산 루프를 듬성듬성 건너뛰어 한 번의 곱셈과 한 번의 덧셈 연산 루프를 네 번의 곱셈과 네 번의 덧셈 연산으로 만든 것입니다. 아니 뭐 이런 할일없는 짓을... 하지만 이렇게 해 줌으로써 프로세서 측면에서는 행렬 인덱싱과 변수 관리, 그리고 파이프라인 관리를 더 효율적으로 할 수 있도록 도와줍니다. 특히나 요즘 출시되는 프로세서들의 장대한 파이프라인에는 언롤링 기법이 매우 큰 도움이 됩니다.
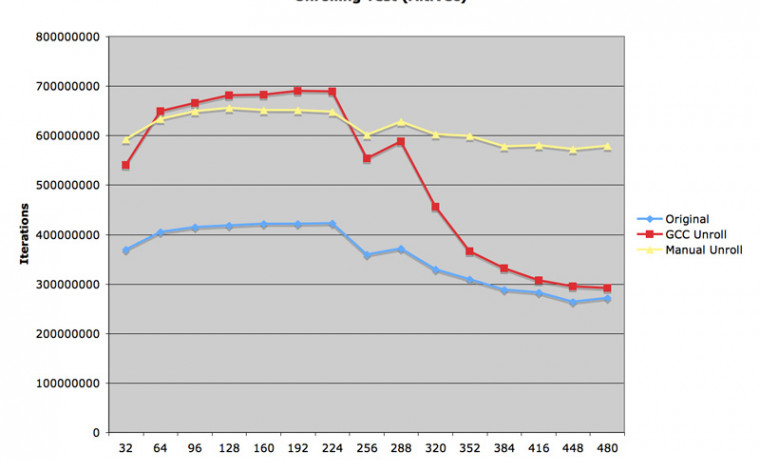
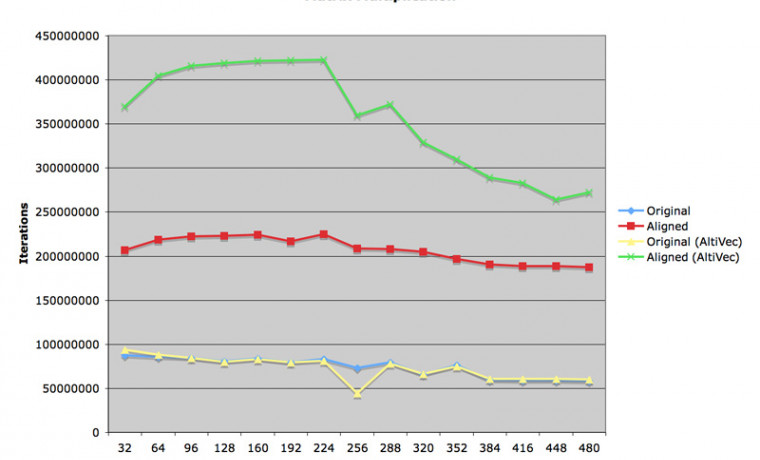
첨부한 그림을 보시면 Xcode 의 "Unroll Loops" 옵션을 켠 다음 실행한 결과가 그렇지 않은 실행 결과보다 최대 80% 이상 빠르게 동작하는 것을 보게 됩니다. 그러나 웬일인지 행렬 크기가 커질수록 성능이 급격히 저하되어 결국 켜나마나한 정도로 줄어들게 됩니다.
위에서 보여드린 코드로 실행한 결과가 노란색 그래프로 출력되어 있습니다. 작은 행렬에서는 GCC 의 최적화 성능보다 약간 떨어지나, 큰 행렬에서의 성능 저하가 GCC 결과에 비해서 그리 급격하지 않은 것을 보게 됩니다.
언롤링은 간단한 방법으로 쉽게 성능을 끌어올릴 수 있는 좋은 방법입니다. 그리고 배밀도 실수 연산에서도 그대로 적용이 가능하므로 매우 유용한 기법입니다.
for( j = 0 ; j < MAT_SIZE ; j++ ) {
for( i = 0 ; i < MAT_SIZE ; i++ ) {
a[ j * MAT_SIZE + i ] = 0.0f ;
}
}
for( k = 0 ; k < MAT_SIZE - 3 ; k+=4 ) {
for( j = 0 ; j < MAT_SIZE ; j++ ) {
t1 = c[ j * MAT_SIZE + k ] ;
t2 = c[ j * MAT_SIZE + k + 1 ] ;
t3 = c[ j * MAT_SIZE + k + 2 ] ;
t4 = c[ j * MAT_SIZE + k + 3 ] ;
for( i = 0 ; i < MAT_SIZE ; i++ ) {
a[ j * MAT_SIZE + i ] +=
b[ k * MAT_SIZE + i ] * t1 +
b[ ( k + 1 ) * MAT_SIZE + i ] * t2 +
b[ ( k + 2 ) * MAT_SIZE + i ] * t3 +
b[ ( k + 3 ) * MAT_SIZE + i ] * t4 ;
}
}
}
for( kk = k ; kk < MAT_SIZE ; kk++ ) {
for( j = 0 ; j < MAT_SIZE ; j++ ) {
t1 = c[ j * MAT_SIZE + kk ] ;
for( i = 0 ; i < MAT_SIZE ; i++ ) {
a[ j * MAT_SIZE + i ] += b[ kk * MAT_SIZE + i ] * t1 ;
}
}
}
보시면 계산 루프를 듬성듬성 건너뛰어 한 번의 곱셈과 한 번의 덧셈 연산 루프를 네 번의 곱셈과 네 번의 덧셈 연산으로 만든 것입니다. 아니 뭐 이런 할일없는 짓을... 하지만 이렇게 해 줌으로써 프로세서 측면에서는 행렬 인덱싱과 변수 관리, 그리고 파이프라인 관리를 더 효율적으로 할 수 있도록 도와줍니다. 특히나 요즘 출시되는 프로세서들의 장대한 파이프라인에는 언롤링 기법이 매우 큰 도움이 됩니다.
첨부한 그림을 보시면 Xcode 의 "Unroll Loops" 옵션을 켠 다음 실행한 결과가 그렇지 않은 실행 결과보다 최대 80% 이상 빠르게 동작하는 것을 보게 됩니다. 그러나 웬일인지 행렬 크기가 커질수록 성능이 급격히 저하되어 결국 켜나마나한 정도로 줄어들게 됩니다.
위에서 보여드린 코드로 실행한 결과가 노란색 그래프로 출력되어 있습니다. 작은 행렬에서는 GCC 의 최적화 성능보다 약간 떨어지나, 큰 행렬에서의 성능 저하가 GCC 결과에 비해서 그리 급격하지 않은 것을 보게 됩니다.
언롤링은 간단한 방법으로 쉽게 성능을 끌어올릴 수 있는 좋은 방법입니다. 그리고 배밀도 실수 연산에서도 그대로 적용이 가능하므로 매우 유용한 기법입니다.
0
0
로그인 후 추천 또는 비추천하실 수 있습니다.
최신글이 없습니다.
최신글이 없습니다.










댓글목록 0