




[App 개발] 코드 최적화 (6) 분기 예측
hongjuny
151.♡.11.172
2005.08.17 10:46
1,478
1
0
0
본문
분기 예측 (Branch Prediction) 이라는 것은 프로세서의 파이프라인이 길어지면서 발생하게 되는 비효율적인 문제를 해결하기 위한 방법으로 도입된 것이지요. 이것이 우리 프로그래밍에 어떤 영향을 미치게 되는지를 살펴보기 위하여 간단한 예제를 작성해 보았습니다.
for( k = 1 ; k < MAT_SIZE - 1 ; k++ ) {
for( j = 1 ; j < 3 ; j++ ) {
for( i = 2 ; i < MAT_SIZE - 1 ; i++ ) {
a[ j * MAT_SIZE + i ] = ( 1.0f - px - py - pz ) * b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i ] +
0.5f * px * ( b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i + 1 ] + b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i + 1 ] ) +
0.5f * py * ( b[ ( k * MAT_SIZE + j + 1 ) * MAT_SIZE + i ] + b[ ( k * MAT_SIZE + j - 1 ) * MAT_SIZE + i ] ) +
0.5f * pz * ( b[ ( ( k + 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] + b[ ( ( k - 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] ) ;
if( k < MAT_SIZE / 2 ) {
c[ j * MAT_SIZE + i ] = a[ j * MAT_SIZE + i ] ;
} else {
b[ ( ( k - 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] = c[ j * MAT_SIZE + i ] ;
c[ j * MAT_SIZE + i ] = a[ j * MAT_SIZE + i ] ;
}
}
}
}
무지막지해 보이는 필터링 루틴 뒤에 짧은 분기 루틴이 있습니다. 루프 한 번 돌 때마다 계속해서 k 값이 MAT_SIZE / 2 보다 작은지를 검사하게 될 것이므로 당연히 속도가 저하되어야 하겠지요. 그래서 다음과 같은 코드를 작성했다고 합시다.
for( k = 1 ; k < MAT_SIZE - 1 ; k++ ) {
for( j = 1 ; j < 3 ; j++ ) {
for( i = 1 ; i < MAT_SIZE - 1 ; i++ ) {
a[ j * MAT_SIZE + i ] = ( 1.0f - px - py - pz ) * b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i ] +
0.5f * px * ( b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i + 1 ] + b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i + 1 ] ) +
0.5f * py * ( b[ ( k * MAT_SIZE + j + 1 ) * MAT_SIZE + i ] + b[ ( k * MAT_SIZE + j - 1 ) * MAT_SIZE + i ] ) +
0.5f * pz * ( b[ ( ( k + 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] + b[ ( ( k - 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] ) ;
}
}
if( k < MAT_SIZE / 2 ) {
for( j = 1 ; j < 3 ; j++ ) {
for( i = 1 ; i < MAT_SIZE ; i++ ) {
c[ j * MAT_SIZE + i ] = a[ j * MAT_SIZE + i ] ;
}
}
} else {
for( j = 1 ; j < 3 ; j++ ) {
for( i = 1 ; i < MAT_SIZE ; i++ ) {
b[ ( ( k - 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] = c[ j * MAT_SIZE + i ] ;
c[ j * MAT_SIZE + i ] = a[ j * MAT_SIZE + i ] ;
}
}
}
}
여기서는 조건문을 바깥으로 빼냄으로서 분기 명령 실행 횟수를 심하게 줄여 놓은 것입니다.
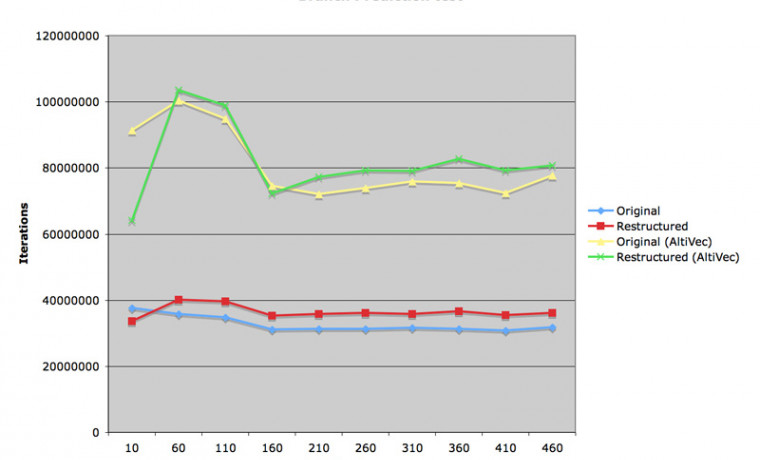
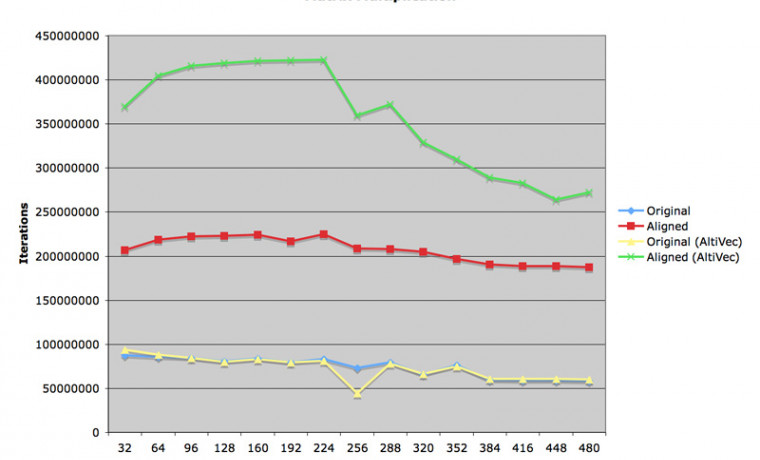
첫 번재 첨부 그림을 보시면, 이 두 코드의 실행 속도는 거의 차이가 없다는 것을 볼 수 있습니다. 오히려 행렬의 크기가 작을 때에는 일부러 수정한 코드의 속도가 느리기까지 합니다. 이 결과는 Auto Vectorization 을 선택한 결과에서도 비슷하게 나타났습니다.
따라서, 루프 내에 조건명령을 넣는 것을 겁내실 필요가 별로 없을 것 같습니다.
하지만 조건문으로 인해서 선택되는 명령이 간단하지 않은 경우는 어떨까요?
for( k = 1 ; k < MAT_SIZE - 1 ; k++ ) {
for( j = 1 ; j < 3 ; j++ ) {
for( i = 2 ; i < MAT_SIZE - 1 ; i++ ) {
if( k < MAT_SIZE / 2 ) {
a[ j * MAT_SIZE + i ] = ( 1.0f - px - py - pz ) * b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i ] +
0.5f * px * ( b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i + 1 ] + b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i + 1 ] ) +
0.5f * py * ( b[ ( k * MAT_SIZE + j + 1 ) * MAT_SIZE + i ] + b[ ( k * MAT_SIZE + j - 1 ) * MAT_SIZE + i ] ) +
0.5f * pz * ( b[ ( ( k + 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] + b[ ( ( k - 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] ) ;
} else {
a[ j * MAT_SIZE + i ] = ( 1.0f - px - py - pz ) * b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i ] +
0.5f * px * ( b[ ( ( k + 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] + b[ ( ( k - 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] ) +
0.5f * py * ( b[ ( k * MAT_SIZE + j + 1 ) * MAT_SIZE + i ] + b[ ( k * MAT_SIZE + j - 1 ) * MAT_SIZE + i ] ) +
0.5f * pz * ( b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i + 1 ] + b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i - 1 ] ) ;
}
}
}
}
조건문에 따라서 b 매트릭스의 방향이 완전히 뒤바뀌는 코드입니다. 이것도 내부 조건문을 밖으로 빼내어 두 개의 루프로 분리시킨 다음 속도를 측정해 보았습니다.
for( k = 1 ; k < MAT_SIZE - 1 ; k++ ) {
if( k < MAT_SIZE / 2 ) {
for( j = 1 ; j < 3 ; j++ ) {
for( i = 2 ; i < MAT_SIZE - 1 ; i++ ) {
a[ j * MAT_SIZE + i ] = ( 1.0f - px - py - pz ) * b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i ] +
0.5f * px * ( b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i + 1 ] + b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i + 1 ] ) +
0.5f * py * ( b[ ( k * MAT_SIZE + j + 1 ) * MAT_SIZE + i ] + b[ ( k * MAT_SIZE + j - 1 ) * MAT_SIZE + i ] ) +
0.5f * pz * ( b[ ( ( k + 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] + b[ ( ( k - 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] ) ;
}
}
} else {
for( j = 1 ; j < 3 ; j++ ) {
for( i = 2 ; i < MAT_SIZE - 1 ; i++ ) {
a[ j * MAT_SIZE + i ] = ( 1.0f - px - py - pz ) * b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i ] +
0.5f * px * ( b[ ( ( k + 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] + b[ ( ( k - 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] ) +
0.5f * py * ( b[ ( k * MAT_SIZE + j + 1 ) * MAT_SIZE + i ] + b[ ( k * MAT_SIZE + j - 1 ) * MAT_SIZE + i ] ) +
0.5f * pz * ( b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i + 1 ] + b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i - 1 ] ) ;
}
}
}
}
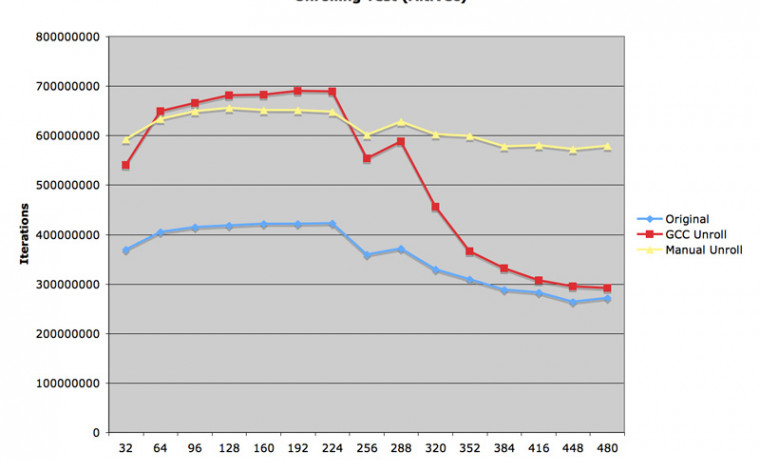
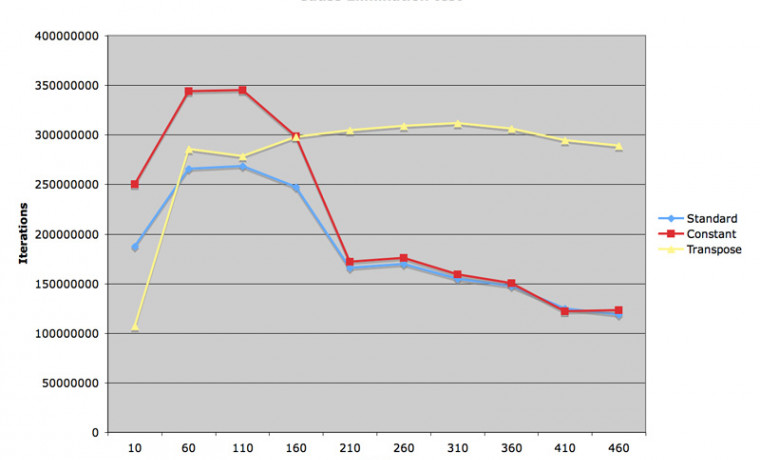
속도 차이가 조금 더 뚜렷하게 나타나기 시작하는 것을 알 수 있습니다.
결론적으로 말해서 PowerPC G5 에서 gcc 로 프로그램을 작성할 경우에는 아직까지는 되도록이면 분기문을 많이 거치지 않도록 코드를 재정렬하는 것이 속도 향상에 도움이 될 것이라는 판단입니다.
ps. 첫 번째 코드 예제를 AMD Opteron 에서 비싼 컴파일러로 수행해 보면 반대로 기본 코드가 재정렬된 코드보다 훨씬 더 빠른 속도를 나타내었습니다. 아... 이상하고 요상한 컴퓨터 나라...
for( k = 1 ; k < MAT_SIZE - 1 ; k++ ) {
for( j = 1 ; j < 3 ; j++ ) {
for( i = 2 ; i < MAT_SIZE - 1 ; i++ ) {
a[ j * MAT_SIZE + i ] = ( 1.0f - px - py - pz ) * b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i ] +
0.5f * px * ( b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i + 1 ] + b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i + 1 ] ) +
0.5f * py * ( b[ ( k * MAT_SIZE + j + 1 ) * MAT_SIZE + i ] + b[ ( k * MAT_SIZE + j - 1 ) * MAT_SIZE + i ] ) +
0.5f * pz * ( b[ ( ( k + 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] + b[ ( ( k - 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] ) ;
if( k < MAT_SIZE / 2 ) {
c[ j * MAT_SIZE + i ] = a[ j * MAT_SIZE + i ] ;
} else {
b[ ( ( k - 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] = c[ j * MAT_SIZE + i ] ;
c[ j * MAT_SIZE + i ] = a[ j * MAT_SIZE + i ] ;
}
}
}
}
무지막지해 보이는 필터링 루틴 뒤에 짧은 분기 루틴이 있습니다. 루프 한 번 돌 때마다 계속해서 k 값이 MAT_SIZE / 2 보다 작은지를 검사하게 될 것이므로 당연히 속도가 저하되어야 하겠지요. 그래서 다음과 같은 코드를 작성했다고 합시다.
for( k = 1 ; k < MAT_SIZE - 1 ; k++ ) {
for( j = 1 ; j < 3 ; j++ ) {
for( i = 1 ; i < MAT_SIZE - 1 ; i++ ) {
a[ j * MAT_SIZE + i ] = ( 1.0f - px - py - pz ) * b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i ] +
0.5f * px * ( b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i + 1 ] + b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i + 1 ] ) +
0.5f * py * ( b[ ( k * MAT_SIZE + j + 1 ) * MAT_SIZE + i ] + b[ ( k * MAT_SIZE + j - 1 ) * MAT_SIZE + i ] ) +
0.5f * pz * ( b[ ( ( k + 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] + b[ ( ( k - 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] ) ;
}
}
if( k < MAT_SIZE / 2 ) {
for( j = 1 ; j < 3 ; j++ ) {
for( i = 1 ; i < MAT_SIZE ; i++ ) {
c[ j * MAT_SIZE + i ] = a[ j * MAT_SIZE + i ] ;
}
}
} else {
for( j = 1 ; j < 3 ; j++ ) {
for( i = 1 ; i < MAT_SIZE ; i++ ) {
b[ ( ( k - 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] = c[ j * MAT_SIZE + i ] ;
c[ j * MAT_SIZE + i ] = a[ j * MAT_SIZE + i ] ;
}
}
}
}
여기서는 조건문을 바깥으로 빼냄으로서 분기 명령 실행 횟수를 심하게 줄여 놓은 것입니다.
첫 번재 첨부 그림을 보시면, 이 두 코드의 실행 속도는 거의 차이가 없다는 것을 볼 수 있습니다. 오히려 행렬의 크기가 작을 때에는 일부러 수정한 코드의 속도가 느리기까지 합니다. 이 결과는 Auto Vectorization 을 선택한 결과에서도 비슷하게 나타났습니다.
따라서, 루프 내에 조건명령을 넣는 것을 겁내실 필요가 별로 없을 것 같습니다.
하지만 조건문으로 인해서 선택되는 명령이 간단하지 않은 경우는 어떨까요?
for( k = 1 ; k < MAT_SIZE - 1 ; k++ ) {
for( j = 1 ; j < 3 ; j++ ) {
for( i = 2 ; i < MAT_SIZE - 1 ; i++ ) {
if( k < MAT_SIZE / 2 ) {
a[ j * MAT_SIZE + i ] = ( 1.0f - px - py - pz ) * b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i ] +
0.5f * px * ( b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i + 1 ] + b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i + 1 ] ) +
0.5f * py * ( b[ ( k * MAT_SIZE + j + 1 ) * MAT_SIZE + i ] + b[ ( k * MAT_SIZE + j - 1 ) * MAT_SIZE + i ] ) +
0.5f * pz * ( b[ ( ( k + 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] + b[ ( ( k - 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] ) ;
} else {
a[ j * MAT_SIZE + i ] = ( 1.0f - px - py - pz ) * b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i ] +
0.5f * px * ( b[ ( ( k + 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] + b[ ( ( k - 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] ) +
0.5f * py * ( b[ ( k * MAT_SIZE + j + 1 ) * MAT_SIZE + i ] + b[ ( k * MAT_SIZE + j - 1 ) * MAT_SIZE + i ] ) +
0.5f * pz * ( b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i + 1 ] + b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i - 1 ] ) ;
}
}
}
}
조건문에 따라서 b 매트릭스의 방향이 완전히 뒤바뀌는 코드입니다. 이것도 내부 조건문을 밖으로 빼내어 두 개의 루프로 분리시킨 다음 속도를 측정해 보았습니다.
for( k = 1 ; k < MAT_SIZE - 1 ; k++ ) {
if( k < MAT_SIZE / 2 ) {
for( j = 1 ; j < 3 ; j++ ) {
for( i = 2 ; i < MAT_SIZE - 1 ; i++ ) {
a[ j * MAT_SIZE + i ] = ( 1.0f - px - py - pz ) * b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i ] +
0.5f * px * ( b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i + 1 ] + b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i + 1 ] ) +
0.5f * py * ( b[ ( k * MAT_SIZE + j + 1 ) * MAT_SIZE + i ] + b[ ( k * MAT_SIZE + j - 1 ) * MAT_SIZE + i ] ) +
0.5f * pz * ( b[ ( ( k + 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] + b[ ( ( k - 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] ) ;
}
}
} else {
for( j = 1 ; j < 3 ; j++ ) {
for( i = 2 ; i < MAT_SIZE - 1 ; i++ ) {
a[ j * MAT_SIZE + i ] = ( 1.0f - px - py - pz ) * b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i ] +
0.5f * px * ( b[ ( ( k + 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] + b[ ( ( k - 1 ) * MAT_SIZE + j ) * MAT_SIZE + i ] ) +
0.5f * py * ( b[ ( k * MAT_SIZE + j + 1 ) * MAT_SIZE + i ] + b[ ( k * MAT_SIZE + j - 1 ) * MAT_SIZE + i ] ) +
0.5f * pz * ( b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i + 1 ] + b[ ( k * MAT_SIZE + j ) * MAT_SIZE + i - 1 ] ) ;
}
}
}
}
속도 차이가 조금 더 뚜렷하게 나타나기 시작하는 것을 알 수 있습니다.
결론적으로 말해서 PowerPC G5 에서 gcc 로 프로그램을 작성할 경우에는 아직까지는 되도록이면 분기문을 많이 거치지 않도록 코드를 재정렬하는 것이 속도 향상에 도움이 될 것이라는 판단입니다.
ps. 첫 번째 코드 예제를 AMD Opteron 에서 비싼 컴파일러로 수행해 보면 반대로 기본 코드가 재정렬된 코드보다 훨씬 더 빠른 속도를 나타내었습니다. 아... 이상하고 요상한 컴퓨터 나라...
0
0
로그인 후 추천 또는 비추천하실 수 있습니다.
최신글이 없습니다.
최신글이 없습니다.










댓글목록 1
원종호님의 댓글
- 원종호님의 홈
- 전체게시물
- 아이디로 검색
222.♡.102.134 2005.10.07 13:09좋은 정보 감사합니다..^^ 전공이 전자라서 나중에 프로세서 쪽으로 갈까 하는데.... 도움이 많이 되었네요^^;