




[App 개발] CUDA, Supercomputing for the Masses (7)
hongjuny
96.♡.163.112
2009.08.26 10:06
1,848
0
0
0
본문
- 차세대 CUDA 하드웨어 활용하기
6 장에서 CUDA 프로파일러를 이용하여 글로벌 메모리를 확인해 보았습니다. 이번에는 차세대 CUDA 하드웨어에 대해 살펴보려 합니다.
CUDA 와 CUDA 지원 장치는 세대를 거듭할수록 더 향상된 성능을 갖추도록 서로 발전해 왔습니다. NVIDIA 가 선보인 최신 GeForce 200 시리즈와 Tesla 10 시리즈는 지난 세대에 비해 동일 가격에 두 배 정도 성능 향상을 나타내었고, 특히 200 시리즈에는 몇 가지 새로운 기능이 추가되어 있습니다.
G80 이 6억 9천만 개의 트랜지스터를 집적한 것에 비해 GTX 280 은 14억 개의 트랜지스터를 집적하였습니다. NVIDIA 는 차세대 하드웨어에 두 배의 성능을 집적한 셈입니다. 경험상 NVIDIA 는 200 시리즈에서 이 트랜지스터들을 매우 잘 이용했습니다. 특별한 변경 없이도 제 단밀도 실수 연산은 구 세대 G80 하드웨어에 비해 새 하드웨어에서 대략 두 배 속도를 내었으니까요.
다음은 200 시리즈 아키텍쳐의 새로운 성능을 요약한 것입니다.
* 하드웨어에서 배밀도 실수 연산 지원 (GTX280 에 30 개의 64비트 부동소숫점 유닛 내장)
* 글로벌 메모리가 더 커지고 빨라지고 사용이 간편해졌다. 협동 규칙이 쉬워져서, 글로벌 메모리 성능을 쉽게 끌어낼 수 있다. 글로벌 메모리 대역폭은 초당 100 GB 이상, G80 하드웨어에 비해 두 배 가까이 빨라진 값
* 하드웨어 쓰레드 당 단밀도 실수 레지스터 갯수가 두 배로 증가 (배밀도 연산시 기존 아키텍쳐와 동일한 레지스터 갯수)
* 200 시리즈는 공유 메모리에 32비트 atomic signed and unsigned 정수 기능, 글로벌 메모리에 64비트 기능
* 200 시리즈에 워프 vote 기능 내장
* 쓰레드 프로세서 갯수가 128 개에서 240 개로 두 배 가량 증가, 멀티프로세서 당 더 많은 갯수의 활성 워프와 활성 쓰레드 지원
* 200 시리즈에는 MAD 와 MUL 을 동시에 수행할 수 있도록 하드웨어 성능 향상, 알고리듬에 따라서 최대 성능을 끌어낼 수 있는 기능
이런 내용이 CUDA 에 미치는 영향을 살펴봅시다.
여러 분야에서 가장 요긴한 기능은 배밀도 실수 연산의 하드웨어 지원입니다. NVIDIA GPU의 속도와 대규모 병렬처리는 슈퍼컴퓨팅을 대중화시켰습니다. 엄청난 규모의 데이터 처리에 있어서 (단밀도 부동소숫점의)실수 오차는 쉽게 누적되어 결과값을 쓸모없게 만들어 버립니다. 예를 들어 물리 시뮬레이션같은 경우 쉽게 비 물리적인 현상을 보이게 되면서 그간 작업한 시뮬레이션을 한 순간에 불안정하게 만들면서 infinity 나 NaN 같은 어이없는 값을 도출해 냅니다. 모든 컴퓨팅 문제에 반드시 필요한 것은 아니지만, 고밀도 부동소숫점 표현 (64비트 배밀도 실수같은) 은 큰 도움이 됩니다. (차후에 단밀도 실수 연산과 배밀도 실수 연산을 조합해 결과 계산 속도를 향상시키는 법을 공부해 보겠습니다.)
200 시리즈는 배밀도 실수 연산을 하드웨어로 구현한 첫 번째 아키텍쳐입니다. 초창기 제품 대부분이 그러하듯 성능 향상에 대한 여지는 항상 남아있습니다 (멀티프로세서 내의 쓰레드 프로세서들이 모두 한 개의 배밀도 실수 연산 하드웨어 유닛에 의존하고 있습니다). 제 경험에 비추어 보았을 때, 계산 정확도를 획득하기 위해 제한적으로 배밀도 실수 연산을 수행할 경우 대략 수 퍼센트 정도의 성능 저하를 나타냅니다. 물론 과제에 따라 다르고 방식에 따라 다르겠지만요.
대부분 프로그래머들이 10 시리즈 아키텍쳐를 이용해 고성능을 쉽게 구현할 수 있을 것입니다.
레지스터 갯수를 두 배로 늘임으로서 NVIDIA 는 CUDA 프로그래머에게 충분한 단밀도 실수 데이터를 레지스터로 처리하게 함으로써 글로벌 메모리를 사용하면서 생기는 병목 현상을 쉽게 해소할 수 있게끔 하였습니다. 배밀도 실수 처리에는 단밀도보다 두 배(배밀도 8바이트, 단밀도 4바이트)의 메모리가 필요하므로, 200 시리즈의 배밀도 실수 레지스터 갯수는 G80 이나 G92 아키텍쳐의 단밀도 실수 레지스터의 갯수와 동일하게 됩니다.
글로벌 메모리의 대역폭은 두 배 가까이 증가하였습니다.
10 시리즈 보드는 초당 100 GB 의 글로벌 메모리 대역폭을 가집니다. 32비트 실수의 경우 10 시리즈의 글로벌 메모리 대역폭은 G80 이나 G92 아키텍쳐에 비해 좋지 않습니다. 왜냐하면 쓰레드 프로세서의 숫자가 두 배로 증가하였기 때문입니다.
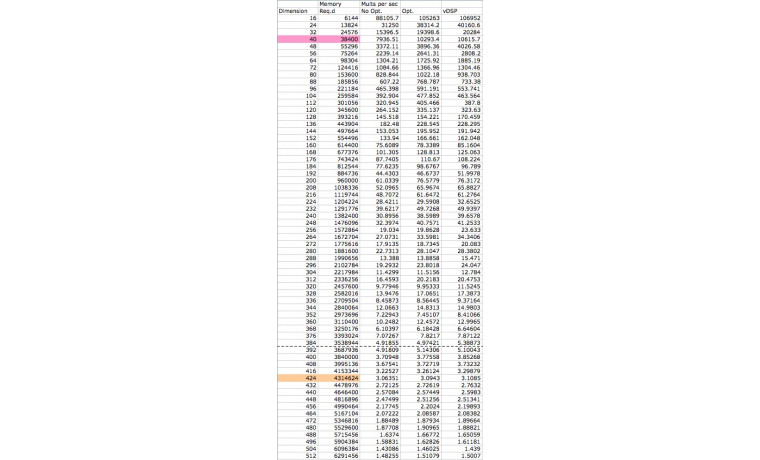
< 표 1 >
배밀도 실수 (64비트 실수) 성능은 멀티프로세서(8 쓰레드 프로세서) 당 단 한 개의 배밀도 실수 계산 유닛밖에 없고 배밀도 연산에는 두 배의 대역폭을 필요로 한다는 점 등을 고려해야 합니다. 200 시리즈를 사용하는 CUDA 개발자들은 밴드폭에 제약을 받던 단밀도 실수 계산 프로그램이 배밀도 계산으로 변경되었을 때 계산 성능에 제약을 받기 시작하게 된다는 것을 발견하게 될 것입니다.
도표에서 나타낸 것처럼 NVIDIA 하드웨어 개발 팀은 동일한 가격에 구 세대 제품보다 두 배 늘어난 메모리 밴드폭에 배밀도 실수 연산 기능을 내장시키는 엄청난 일을 해 내었습니다.
CUDA 프로그램에게 끼치는 장점이라면 200 시리즈의 협동 규칙 완화로 인하여 글로벌 메모리를 고성능으로 쉽게 억세스할 수 있게 되었다는 점입니다. 메모리 사용에 대한 자세한 내용은 CUDA 프로그래밍 가이드 5.2.2 를 참조하세요. 요점을 다음의 세 가지로 정리하면:
* 동일 어드레스를 다중 참조하는 방식 등이 가능. 기존 아키텍쳐에서는 워드 단위를 차례로 억세스해야 했음. 이로서 많은 CUDA 프로그램들이 탁월한 글로벌 메모리 성능을 보유할 수 있으며, CUDA 프로그래머는 글로벌 메모리 억세스 패턴을 지키기 위해 고생할 필요가 없어졌음.
* 만약 하프 워프가 n 개의 세그먼트의 워드를 참조할 경우, 오로지 n 번의 메모리 참조만 필요. 예를 들어 n=2 라면, 기존 아키텍쳐에서는 16 번의 메모리 참조가 필요했지만 이제는 두 번의 참조만 필요.
* 불행히도 미사용 워드도 읽어들여야만 하며, 하드웨어가 최대한 적은 메모리 참조를 수행하더라도 그만큼의 밴드폭 낭비가 일어남.
200 시리즈는 signed 와 unsigned 정수에 대한 atomic 연산을 지원합니다. atomicExch() 는 단밀도 실수 연산도 지원합니다. 아토믹 함수는 read-modify-write 아토믹 연산을 글로벌 혹은 공유 메모리 내 한 개의 32 비트 혹은 64 비트 워드에 수행합니다. 예를 들어, atomicAdd() 는 글로벌 혹은 공유 메모리 특정 어드레스의 32비트 워드를 읽어, 정수값을 더한 후, 동일한 어드레스에 그 값을 저장합니다. 이 작업은 다른 쓰레드의 간섭 없이 정확히 동작하므로 아토믹 입니다. 이 연산이 종료될 때까지 다른 쓰레드는 이 어드레스를 억세스할 수 없습니다.
200 시리즈에는 워프 vote 함수를 지원합니다. 필요한 경우 모든 워프의 쓰레드에게 고속 조건 연산을 무조건 수행하도록 지시할 수 있습니다.
int __all(int predicate);
워프 내 모든 쓰레드에게 특정 조건항을 평가하게 하여, 만약 모두가 non-zero 를 리턴했을 경우 non-zero 를 리턴합니다.
int __any(int predicate);
워프 내 모든 쓰레드에게 특정 조건항을 평가하게 하여, 그 중 어떤 쓰레드라도 non-zero 를 리턴했을 경우 non-zero 를 리턴합니다.
마지막으로 MAD 와 MUL 을 동시 수행하도록 하드웨어가 향상된 것은 응용프로그램에 따라서 FLOP (Floting-point operations) 지수를 최대 성능까지 끌어올릴 수 있도록 해 줍니다.
자세한 사항은 CUDA Zone 포럼을 참조하세요. 그리고 CUDA Programming Guide 최신판을 NVIDIA 웹사이트에서 다운로드하시길 권장합니다. 현재 버젼은 2.0b2 인데, 지금 논의한 새 기능과 API 가 포함되어 있습니다.
지금이 200 시리즈 CUDA 지원 장치로 업그레이드하기 좋은 기회입니다. 치열한 경쟁 덕분에 가격 조건도 좋아졌고, 구입하기에 적기일 것입니다.
6 장에서 CUDA 프로파일러를 이용하여 글로벌 메모리를 확인해 보았습니다. 이번에는 차세대 CUDA 하드웨어에 대해 살펴보려 합니다.
CUDA 와 CUDA 지원 장치는 세대를 거듭할수록 더 향상된 성능을 갖추도록 서로 발전해 왔습니다. NVIDIA 가 선보인 최신 GeForce 200 시리즈와 Tesla 10 시리즈는 지난 세대에 비해 동일 가격에 두 배 정도 성능 향상을 나타내었고, 특히 200 시리즈에는 몇 가지 새로운 기능이 추가되어 있습니다.
G80 이 6억 9천만 개의 트랜지스터를 집적한 것에 비해 GTX 280 은 14억 개의 트랜지스터를 집적하였습니다. NVIDIA 는 차세대 하드웨어에 두 배의 성능을 집적한 셈입니다. 경험상 NVIDIA 는 200 시리즈에서 이 트랜지스터들을 매우 잘 이용했습니다. 특별한 변경 없이도 제 단밀도 실수 연산은 구 세대 G80 하드웨어에 비해 새 하드웨어에서 대략 두 배 속도를 내었으니까요.
다음은 200 시리즈 아키텍쳐의 새로운 성능을 요약한 것입니다.
* 하드웨어에서 배밀도 실수 연산 지원 (GTX280 에 30 개의 64비트 부동소숫점 유닛 내장)
* 글로벌 메모리가 더 커지고 빨라지고 사용이 간편해졌다. 협동 규칙이 쉬워져서, 글로벌 메모리 성능을 쉽게 끌어낼 수 있다. 글로벌 메모리 대역폭은 초당 100 GB 이상, G80 하드웨어에 비해 두 배 가까이 빨라진 값
* 하드웨어 쓰레드 당 단밀도 실수 레지스터 갯수가 두 배로 증가 (배밀도 연산시 기존 아키텍쳐와 동일한 레지스터 갯수)
* 200 시리즈는 공유 메모리에 32비트 atomic signed and unsigned 정수 기능, 글로벌 메모리에 64비트 기능
* 200 시리즈에 워프 vote 기능 내장
* 쓰레드 프로세서 갯수가 128 개에서 240 개로 두 배 가량 증가, 멀티프로세서 당 더 많은 갯수의 활성 워프와 활성 쓰레드 지원
* 200 시리즈에는 MAD 와 MUL 을 동시에 수행할 수 있도록 하드웨어 성능 향상, 알고리듬에 따라서 최대 성능을 끌어낼 수 있는 기능
이런 내용이 CUDA 에 미치는 영향을 살펴봅시다.
여러 분야에서 가장 요긴한 기능은 배밀도 실수 연산의 하드웨어 지원입니다. NVIDIA GPU의 속도와 대규모 병렬처리는 슈퍼컴퓨팅을 대중화시켰습니다. 엄청난 규모의 데이터 처리에 있어서 (단밀도 부동소숫점의)실수 오차는 쉽게 누적되어 결과값을 쓸모없게 만들어 버립니다. 예를 들어 물리 시뮬레이션같은 경우 쉽게 비 물리적인 현상을 보이게 되면서 그간 작업한 시뮬레이션을 한 순간에 불안정하게 만들면서 infinity 나 NaN 같은 어이없는 값을 도출해 냅니다. 모든 컴퓨팅 문제에 반드시 필요한 것은 아니지만, 고밀도 부동소숫점 표현 (64비트 배밀도 실수같은) 은 큰 도움이 됩니다. (차후에 단밀도 실수 연산과 배밀도 실수 연산을 조합해 결과 계산 속도를 향상시키는 법을 공부해 보겠습니다.)
200 시리즈는 배밀도 실수 연산을 하드웨어로 구현한 첫 번째 아키텍쳐입니다. 초창기 제품 대부분이 그러하듯 성능 향상에 대한 여지는 항상 남아있습니다 (멀티프로세서 내의 쓰레드 프로세서들이 모두 한 개의 배밀도 실수 연산 하드웨어 유닛에 의존하고 있습니다). 제 경험에 비추어 보았을 때, 계산 정확도를 획득하기 위해 제한적으로 배밀도 실수 연산을 수행할 경우 대략 수 퍼센트 정도의 성능 저하를 나타냅니다. 물론 과제에 따라 다르고 방식에 따라 다르겠지만요.
대부분 프로그래머들이 10 시리즈 아키텍쳐를 이용해 고성능을 쉽게 구현할 수 있을 것입니다.
레지스터 갯수를 두 배로 늘임으로서 NVIDIA 는 CUDA 프로그래머에게 충분한 단밀도 실수 데이터를 레지스터로 처리하게 함으로써 글로벌 메모리를 사용하면서 생기는 병목 현상을 쉽게 해소할 수 있게끔 하였습니다. 배밀도 실수 처리에는 단밀도보다 두 배(배밀도 8바이트, 단밀도 4바이트)의 메모리가 필요하므로, 200 시리즈의 배밀도 실수 레지스터 갯수는 G80 이나 G92 아키텍쳐의 단밀도 실수 레지스터의 갯수와 동일하게 됩니다.
글로벌 메모리의 대역폭은 두 배 가까이 증가하였습니다.
10 시리즈 보드는 초당 100 GB 의 글로벌 메모리 대역폭을 가집니다. 32비트 실수의 경우 10 시리즈의 글로벌 메모리 대역폭은 G80 이나 G92 아키텍쳐에 비해 좋지 않습니다. 왜냐하면 쓰레드 프로세서의 숫자가 두 배로 증가하였기 때문입니다.
< 표 1 >
배밀도 실수 (64비트 실수) 성능은 멀티프로세서(8 쓰레드 프로세서) 당 단 한 개의 배밀도 실수 계산 유닛밖에 없고 배밀도 연산에는 두 배의 대역폭을 필요로 한다는 점 등을 고려해야 합니다. 200 시리즈를 사용하는 CUDA 개발자들은 밴드폭에 제약을 받던 단밀도 실수 계산 프로그램이 배밀도 계산으로 변경되었을 때 계산 성능에 제약을 받기 시작하게 된다는 것을 발견하게 될 것입니다.
도표에서 나타낸 것처럼 NVIDIA 하드웨어 개발 팀은 동일한 가격에 구 세대 제품보다 두 배 늘어난 메모리 밴드폭에 배밀도 실수 연산 기능을 내장시키는 엄청난 일을 해 내었습니다.
CUDA 프로그램에게 끼치는 장점이라면 200 시리즈의 협동 규칙 완화로 인하여 글로벌 메모리를 고성능으로 쉽게 억세스할 수 있게 되었다는 점입니다. 메모리 사용에 대한 자세한 내용은 CUDA 프로그래밍 가이드 5.2.2 를 참조하세요. 요점을 다음의 세 가지로 정리하면:
* 동일 어드레스를 다중 참조하는 방식 등이 가능. 기존 아키텍쳐에서는 워드 단위를 차례로 억세스해야 했음. 이로서 많은 CUDA 프로그램들이 탁월한 글로벌 메모리 성능을 보유할 수 있으며, CUDA 프로그래머는 글로벌 메모리 억세스 패턴을 지키기 위해 고생할 필요가 없어졌음.
* 만약 하프 워프가 n 개의 세그먼트의 워드를 참조할 경우, 오로지 n 번의 메모리 참조만 필요. 예를 들어 n=2 라면, 기존 아키텍쳐에서는 16 번의 메모리 참조가 필요했지만 이제는 두 번의 참조만 필요.
* 불행히도 미사용 워드도 읽어들여야만 하며, 하드웨어가 최대한 적은 메모리 참조를 수행하더라도 그만큼의 밴드폭 낭비가 일어남.
200 시리즈는 signed 와 unsigned 정수에 대한 atomic 연산을 지원합니다. atomicExch() 는 단밀도 실수 연산도 지원합니다. 아토믹 함수는 read-modify-write 아토믹 연산을 글로벌 혹은 공유 메모리 내 한 개의 32 비트 혹은 64 비트 워드에 수행합니다. 예를 들어, atomicAdd() 는 글로벌 혹은 공유 메모리 특정 어드레스의 32비트 워드를 읽어, 정수값을 더한 후, 동일한 어드레스에 그 값을 저장합니다. 이 작업은 다른 쓰레드의 간섭 없이 정확히 동작하므로 아토믹 입니다. 이 연산이 종료될 때까지 다른 쓰레드는 이 어드레스를 억세스할 수 없습니다.
200 시리즈에는 워프 vote 함수를 지원합니다. 필요한 경우 모든 워프의 쓰레드에게 고속 조건 연산을 무조건 수행하도록 지시할 수 있습니다.
int __all(int predicate);
워프 내 모든 쓰레드에게 특정 조건항을 평가하게 하여, 만약 모두가 non-zero 를 리턴했을 경우 non-zero 를 리턴합니다.
int __any(int predicate);
워프 내 모든 쓰레드에게 특정 조건항을 평가하게 하여, 그 중 어떤 쓰레드라도 non-zero 를 리턴했을 경우 non-zero 를 리턴합니다.
마지막으로 MAD 와 MUL 을 동시 수행하도록 하드웨어가 향상된 것은 응용프로그램에 따라서 FLOP (Floting-point operations) 지수를 최대 성능까지 끌어올릴 수 있도록 해 줍니다.
자세한 사항은 CUDA Zone 포럼을 참조하세요. 그리고 CUDA Programming Guide 최신판을 NVIDIA 웹사이트에서 다운로드하시길 권장합니다. 현재 버젼은 2.0b2 인데, 지금 논의한 새 기능과 API 가 포함되어 있습니다.
지금이 200 시리즈 CUDA 지원 장치로 업그레이드하기 좋은 기회입니다. 치열한 경쟁 덕분에 가격 조건도 좋아졌고, 구입하기에 적기일 것입니다.
0
0
로그인 후 추천 또는 비추천하실 수 있습니다.
최신글이 없습니다.
최신글이 없습니다.







댓글목록 0